java垃圾回收
一、jvm内存结构
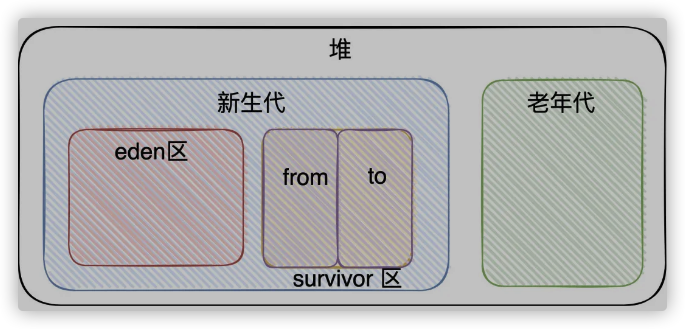
嗯,前面提到了堆分了「新生代」和 「老年代」,「新生代」又分为「Eden」和「Survivor」区,「Survivor」区又分为「From Survivor」和「To Survivor」区
二、垃圾回收机制
- 背景
我们使用Java的时候,会创建很多对象,但我们未曾「手动」将这些对象进行清除; 而如果用C/C++语言的时候,用完是需要自己free(释放)掉的; 那为什么在写Java的时候不用我们自己手动释放"垃圾"呢?原因很简单,JVM帮我们做了(自动回收垃圾)
- 垃圾定义
我个人对垃圾的定义:只要对象不再被使用了,那我们就认为该对象就是垃圾,对象所占用的空间就可以被回收
判断垃圾不再被使用
常用算法有2个:引用计数法、可达性分析法
引用计数法思路很简单:当对象被引用则+1,但对象引用失败则-1。当计数器为0时,说明对象不再被引用,可以被可回收 缺点:引用计数法最明显的缺点就是:如果对象存在循环依赖,那就无法定位该对象是否应该被回收(A依赖B,B依赖A)
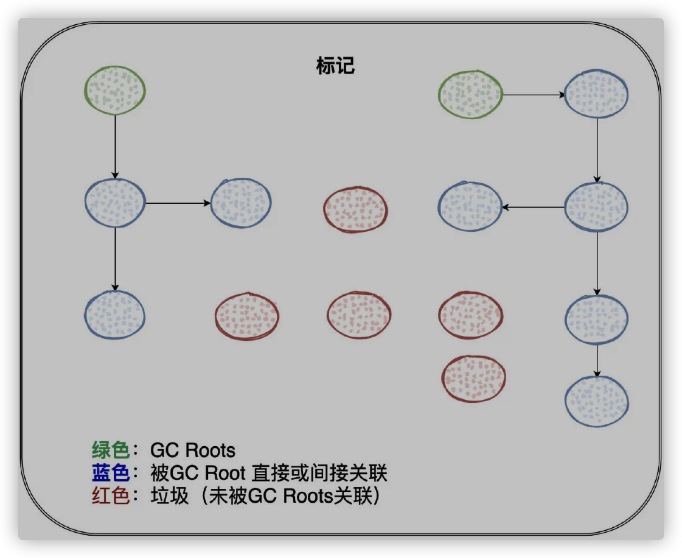
另一种就是可达性分析法:它从「GCR oots」开始向下搜索,当对象到「GCRoots」都没有任何引用相连时,说明对象是不可用的,可以被回收。 「GC Roots」是一组必须「活跃」的引用。 从「GC Root」出发,程序通过直接引用或者间接引用,能够找到可能正在被使用的对象。
例子:比如我们上次不是聊到JVM内存结构中的虚拟机栈吗,虚拟机栈里不是有栈帧吗,栈帧不是有局部变量吗?局部变量不就存储着引用嘛。 那如果栈帧位于虚拟机栈的栈顶,是不是说明这个栈帧是活跃的(换言之,是线程正在被调用的) 既然是线程正在调用的,那栈帧里的指向「堆」的对象引用,是不是一定是「活跃」的引用?
所以,当前活跃的栈帧指向堆里的对象引用就可以是「GCRoots」
当然,比如类的静态变量引用是「GCRootS」,被「Java本地方法」所引用的对象也是「GCRoots」等等。。。 即:回到理解的重点:「GCRoots」是一组必须「活跃」的「引用」,只要跟「GCRoots」没有直接或者间接引用相连,那就是垃圾 JVM用的就是「可达性分析算法」来判断对象是否为垃圾
- 垃圾回收第一步就是标记
标记哪些没有被「GC Roots」引用的对象
标记完后就可以清除了
标记完之后,我们就可以选择直接「清除」,只要不被「GCRoots」关联的,都可以干掉过程非常简单粗暴。
但也存在很明显的问题 直接清除会有「内存碎片」的问题:可能我有10M的空余内存,但程序申请9M内存空间却申请不下来(10M的内存空间是垃圾清除后的,不连续的)
那解决「内存碎片」的问题也比较简单粗暴,「标记」完,不直接「清除」 我把「标记」存活的对象「复制」到另一块空间,复制完了之后,直接把原有的整块空间给干掉!这样就没有内存碎片的问题了 这种做法缺点又很明显:内存利用率低,得有一块新的区域给我复制(移动)过去
还有一种「折中」的办法,我未必要有一块「大的完整空间」才能解决内存碎片的问题,我只要能在「当前区域」内进行移动 把存活的对象移到一边,把垃圾移到一边,那再将垃圾一起删除掉,不就没有内存碎片了嘛,专业术语叫做整理。
年轻代、老年代 「垃圾回收」是会导致「stop the word」 (应用停止访问) 理解「stop the word」应该很简单吧:回收垃圾的时候,程序是有短暂的时间不能正常继续运作啊。不然JVM在回收的时候,用户线程还「不停止」继续分配修改引用,JVM怎么搞(:
经过研究表明:大部分对象的生命周期都很短,而只有少部分对象可能会存活很长时间
为了使「stop the word」持续的时间尽可能短以及提高并发式GC所能应付的内存分配速率 在很多的垃圾收集器上都会在「物理」或者「逻辑」上,把这两类对象进行区分司P 死得快的对象所占的区域叫做「年轻代」,活得久的对象所占的区域叫做「老年代」
(jdk8及以下分年轻代、老年代;高版本的垃圾收集器ZGC,是没有分代的概念的)
垃圾回收过程:对应几种垃圾回收算法
其实在前面更前面提到了垃圾回收的过程,其实就对应着几种「垃圾回收算法」分别是: 标记清除算法、标记复制算法和标记整理算法【「标记」「复制」「整理」】
jdk8生产环境下常见垃圾回收器
「年轻代」的垃圾收集器有:Serial、Parallel Scavenge、 ParNew 「老年代」的垃圾收集器有:Serial Old、 Parallel Old、CMS
- 看着垃圾收集器有很多,其实还是非常好理解的。Serial是单线程的,Parallel是多线程
- 这些垃圾收集器实际上就是「实现了」垃圾回收算法(标记复制、标记整理以及标记清除算法)
- CMS是比较新的垃圾收集器,它的特点是能够尽可能减少「stopthe word」时间。在垃圾回收时让用户线程和GC线程能够并发执行!
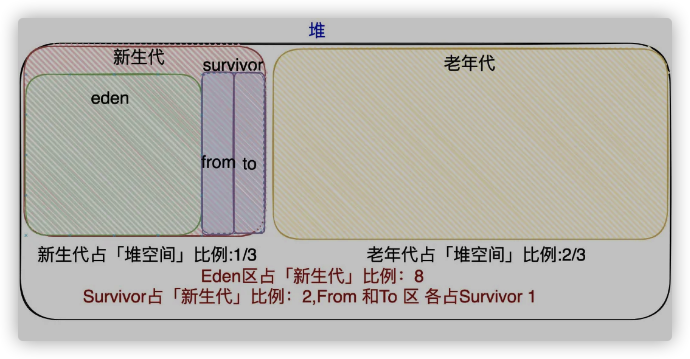
- 「年轻代」的垃圾收集器使用的都是「标记复制算法」 所以在「堆内存」划分中,将年轻代划分出Survivor区(Survivor From和Survivor To),目的就是为了有一块完整的内存空间供垃圾回收器进行拷贝(移动),而新对象都是放入Eden区的。
- 我下面重新画下「堆内存」的图,因为它们的大小是有默认的比例的
新生代何时会变老年代 分2种情况:
- 如果对象太大了,就会直接进入老年代(对象创建时就很大 || Survivor区没办法存下该对象)
- 如果对象太老了,那就会晋升至老年代(每发生一次MinorGC,存活的对象年龄+1,达到默认值15则晋升老年代 || 动态对象年龄判定可以进入老年代)
- 当Eden区空间不足时,就会触发MinorGC
- 那在「年轻代」GC的时候,从GC Roots出发,那不也会扫描到「老年代」的对象吗?那那那..不就相当于全堆扫描吗?
- 这JVM里也有解决办法的。下我的看法 HotSpot虚拟机「老的GC」(G1以下) 是要求整个GC堆在连续的地址空间上 所以会有一条分界线(一侧是老年代,另一侧是年轻代),所以可以通过「地址」就可以判断对象在哪个分代上如
- 当做MonorGC的时候,从GCRoots出发,如果发现「老年代」的对象,那就不往下走了(MonorGC对老年代的区域毫无兴趣)
- 但又有个问题,那如果年轻代」的对象被「老年代」引用了呢?(老年代对象持有年轻代对象的引用),这时候肯定是不能回收掉「年轻代」的对象的?
- HotSpot虚拟机下有「card table」(卡表)来避免全局扫描「老年代」对象
- 「堆内存」的每一小块区域形成「卡页」,卡表实际上就是卡页的集合。当判断一个卡页中有存在对象的跨代引用时,将这个页标记为「脏页」
- 那知道了「卡表」之后,就很好办了。每次MinorGC的时候只需要去「卡表」找到「脏页」,找到后加入至GCRoot,而不用去遍历整个「老年代」的对象了。