java学习路线问题整理
Java 基础
为了能让自己写出更优秀的代码,《Effective Java》、《重构》 这两本书没事也可以看
并发
一些关于并发的小问题,拿来自测:
一、什么是线程和进程? 线程与进程的关系,区别及优缺点?
**Linux****的进程、线程、文件描述符是 什么
**答案:在 Linux 系统中,进程和线程几乎没有区别。
Linux 中的进程就是一个数据结构,看明白就可以理解文件描述符、重定 向、管道命令的底层工作原理,最后我们从操作系统的角度看看为什么说线 程和进程基本没有区别。
1、进程是什么
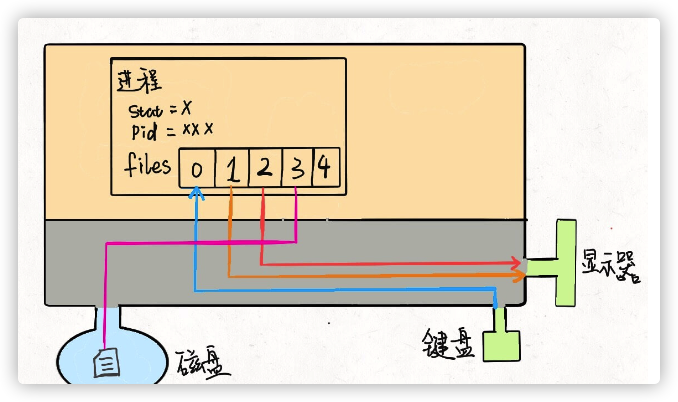
首先,抽象地来说,我们的计算机就是这个东⻄:
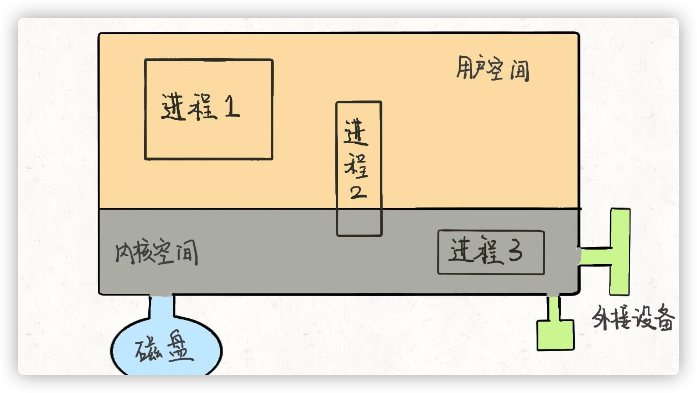
这个大的矩形表示计算机的内存空间,其中的小矩形代表进程,左下角的圆 形表示磁盘,右下角的图形表示一些输入输出设备,比如鼠标键盘显示器等 等。另外,注意到内存空间被划分为了两块,上半部分表示用户空间,下半部分表示内核空间。
用户空间装着用户进程需要使用的资源,比如你在程序代码里开一个数组, 这个数组肯定存在用户空间;内核空间存放内核进程需要加载的系统资源, 这一些资源一般是不允许用户访问的。但是注意有的用户进程会共享一些内 核空间的资源,比如一些动态链接库等等。
我们用 C 语言写一个 hello 程序,编译后得到一个可执行文件,在命令行运 行就可以打印出一句 hello world,然后程序退出。在操作系统层面,就是新 建了一个进程,这个进程将我们编译出来的可执行文件读入内存空间,然后 执行,最后退出。
你编译好的那个可执行程序只是一个文件,不是进程,可执行文件必须要载 入内存,包装成一个进程才能真正跑起来。进程是要依靠操作系统创建的, 每个进程都有它的固有属性,比如进程号(PID)、进程状态、打开的文件 等等,进程创建好之后,读入你的程序,你的程序才被系统执行。
那么,操作系统是如何创建进程的呢?对于操作系统,进程就是一个数据结 构,我们直接来看 Linux 的源码:
struct task_struct {
// 进程状态
long state;
// 虚拟内存结构体
struct mm_struct *mm;
// 进程号
pid_t pid;
// 指向父进程的指针
struct task_struct __rcu *parent;
// 子进程列表
struct list_head children;
// 存放文件系统信息的指针
struct fs_struct *fs;
// 一个数组,包含该进程打开的文件指针
struct files_struct *files;
};
task_struct 就是Linux内核对于一个进程的描述,也可以称为「进程描述符」。源码比较复杂,我这里就截取了一小部分比较常⻅的。
其中比较有意思的是 mm 指针和 files 指针。 mm 指向的是进程的虚拟内 存,也就是载入资源和可执行文件的地方; files 指针指向一个数组,这 个数组里装着所有该进程打开的文件的指针。
2、文件描述符是什么
先说 files ,它是一个文件指针数组。一般来说,一个进程会 从 files[0] 读取输入,将输出写入 files[1] ,将错误信息写 入 files[2] 。
举个例子,以我们的角度 C 语言的 printf 函数是向命令行打印字符,但是 从进程的角度来看,就是向 files[1] 写入数据;同理, scanf函数就是进程试图从files[0] 这个文件中读取数据。
每个进程被创建时, files 的前三位被填入默认值,分别指向标准输入 流、标准输出流、标准错误流。我们常说的「文件描述符」就是指这个文件 指针数组的索引,所以程序的文件描述符默认情况下 0 是输入,1 是输出, 2 是错误。
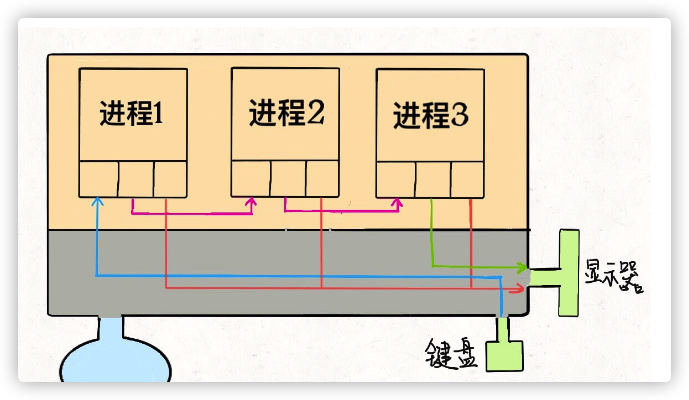
我们可以重新画一幅图:
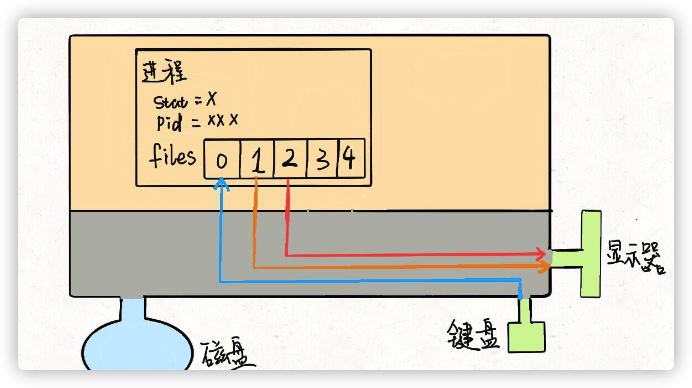
对于一般的计算机,输入流是键盘,输出流是显示器,错误流也是显示器, 所以现在这个进程和内核连了三根线。因为硬件都是由内核管理的,我们的 进程需要通过「系统调用」让内核进程访问硬件资源。
PS:不要忘了,Linux 中一切都被抽象成文件,设备也是文件,可以进行读 和写。
如果我们写的程序需要其他资源,比如打开一个文件进行读写,这也很简单,进行系统调用,让内核把文件打开,这个文件就会被放到 files 的第 4 个位置:
明白了这个原理,输入重定向就很好理解了,程序想读取数据的时候就会 去 files[0] 读取,所以我们只要把 files[0] 指向一个文件,那么程序就会 从这个文件中读取数据,而不是从键盘:
$ command < file.txt
同理,输出重定向就是把 files[1] 指向一个文件,那么程序的输出就不会写入到显示器,而是写入到这个文件中:
错误重定向也是一样的,就不再赘述。 管道符其实也是异曲同工,把一个进程的输出流和另一个进程的输入流接起 一条「管道」,数据就在其中传递,不得不说这种设计思想真的很优美:
$ command > file.txt
$ cmd1 | cmd2 | cmd3
到这里,你可能也看出「Linux 中一切皆文件」设计思路的高明了,不管是 设备、另一个进程、socket 套接字还是真正的文件,全部都可以读写,统一 装进一个简单的 files 数组,进程通过简单的文件描述符访问相应资源, 具体细节交于操作系统,有效解耦,优美高效。
3、线程是什么
首先要明确的是,多进程和多线程都是并发,都可以提高处理器的利用效率,所以现在的关键是,多线程和多进程有啥区别。
为什么说 Linux 中线程和进程基本没有区别呢,因为从 Linux 内核的角度来 看,并没有把线程和进程区别对待。
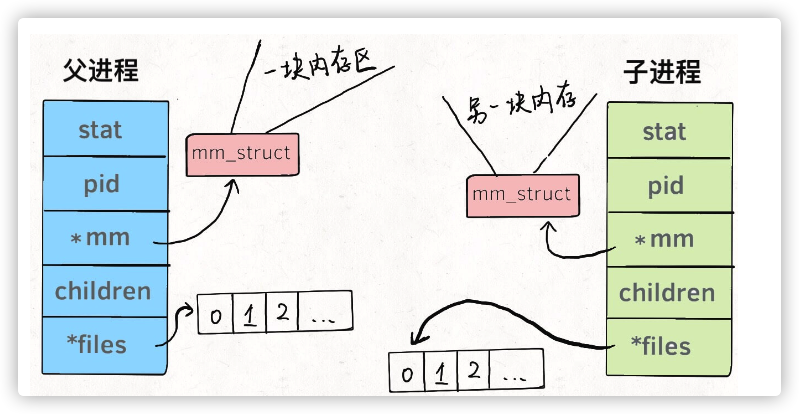
我们知道系统调用 fork() 可以新建一个子进程,函数 pthread() 可以新建 一个线程。但无论线程还是进程,都是用task_struct结构表示的,唯一的 区别就是共享的数据区域不同。
换句话说,线程看起来跟进程没有区别,只是线程的某些数据区域和其父进 程是共享的,而子进程是拷⻉副本,而不是共享。就比如说, mm 结构 和 files 结构在线程中都是共享的,我画两张图你就明白了:
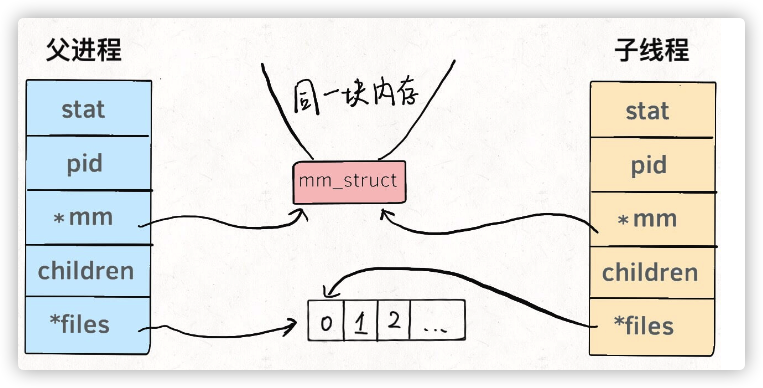
所以说,我们的多线程程序要利用锁机制,避免多个线程同时往同一区域写 入数据,否则可能造成数据错乱。
那么你可能问,既然进程和线程差不多,而且多进程数据不共享,即不存在 数据错乱的问题,为什么多线程的使用比多进程普遍得多呢?
因为现实中数据共享的并发更普遍呀,比如十个人同时从一个账户取十元, 我们希望的是这个共享账户的余额正确减少一百元,而不是希望每人获得一 个账户的拷⻉,每个拷⻉账户减少十元。
当然,必须要说明的是,只有 Linux 系统将线程看做共享数据的进程,不对 其做特殊看待,其他的很多操作系统是对线程和进程区别对待的,线程有其 特有的数据结构,我个人认为不如 Linux 的这种设计简洁,增加了系统的复 杂度。
在 Linux 中新建线程和进程的效率都是很高的,对于新建进程时内存区域拷 ⻉的问题,Linux 采用了 copy-on-write 的策略优化,也就是并不真正复制父 进程的内存空间,而是等到需要写操作时才去复制。所以 Linux 中新建进 程和新建线程都是很迅速的。
二、说说并发与并行的区别?
- 并发:一个处理器同时处理多个任务。
- 并行:多个处理器或者是多核的处理器同时处理多个不同的任务.
前者是逻辑上的同时发生(simultaneous),而后者是物理上的同时发生.
- 并发性(concurrency),又称共行性,是指能处理多个同时性活动的能力,并发事件之间不一定要同一时刻发生。
- 并行(parallelism)是指同时发生的两个并发事件,具有并发的含义,而并发则不一定并行。
来个比喻:并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头。
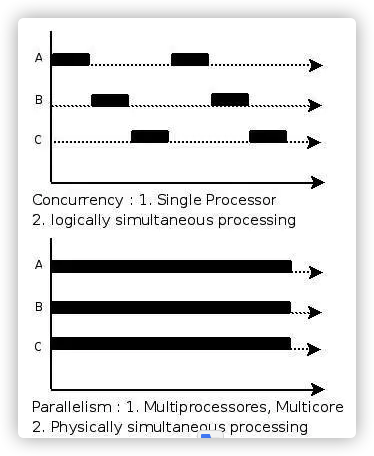
并发与并行的区别
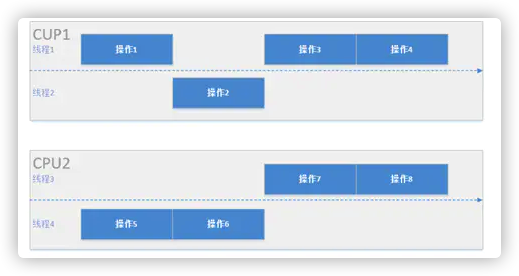
下图反映了一个包含8个操作的任务在一个有两核心的CPU中创建四个线程运行的情况。假设每个核心有两个线程,那么每个CPU中两个线程会交替并发,两个CPU之间的操作会并行运算。单就一个CPU而言两个线程可以解决线程阻塞造成的不流畅问题,其本身运行效率并没有提高,多CPU的并行运算才真正解决了运行效率问题,这也正是并发和并行的区别。
三、为什么要使用多线程呢?
从系统应用上来思考:
- 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间切换和调度的成本远远小于进程。另外,多核 CPU 时代,意味着多个线程可以同时运行,这减少了线程上下文切换的开销;
- 如今的系统,动不动就要求百万级甚至亿万级的并发量,而多线程并发编程,正是开发高并发系统的基础,利用好多线程机制,可以大大提高系统整体的并发能力以及性能。
从计算机背后来探讨:
单核时代: 在单核时代,多线程主要是为了提高 CPU 和 IO 设备的综合利用率。举个例子:当只有一个线程工作的时候,会导致 CPU 计算时,IO 设备空闲;进行 IO 操作时,CPU 空闲。可以简单地理解成,这两者的利用率最高都是 50%左右。但是当有两个线程的时候就不一样了,一个线程执行 CPU 计算时,另外一个线程就可以进行 IO 操作,这样 CPU 和 IO 设备两个的利用率就可以在理想情况下达到 100%;
多核时代: 多核时代多线程主要是为了提高 CPU 利用率。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,CPU 只有一个 CPU 核心被利用到,而创建多个线程,就可以让多个 CPU 核心被利用到,这样就提高了 CPU 的利用率。
四、创建线程有哪几种方式?(a.继承 Thread 类;b.实现 Runnable 接口;c. 使用 Executor 框架;d.使用 FutureTask)
五、说说线程的生命周期和状态?
那么现在我们来了解线程一个完整的生命周期的运行过程,与下图可以看出有:新建 - 就绪 - 运行 - 阻塞 - 死亡五个过程。
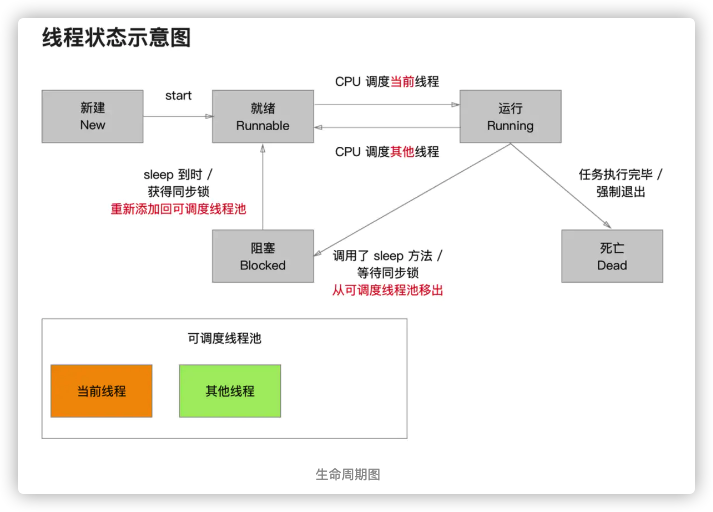
下面我们一个一个的来介绍:
- 新建:刚刚创建还在内存当中,还没有在可调度线程池中,还不能被cpu调度执行工作。
- 就绪:进入调度池,可被调度。
- 运行:CPU负责调度”可调度线程池”中的处于”就绪状态”的线程,线程执行结束之前,状态可能会在”就绪”和”运行”之间来回的切换。“就绪”和”运行”之间的状态切换由CPU来完成,程序员无法干涉
- 阻塞:正在运行的线程,当满足某个条件时,可以用休眠或者锁来阻塞线程的执行,被移出调度池,进入内存,不可执行。
- 死亡:分为两种情况。正常死亡,线程执行结束。非正常死亡,程序突然崩溃/当满足某个条件后,在线程内部强制线程退出,调用exit方法。
exit方法的作用和总结
使当前线程退出.
不能在主线程中调用该方法,会使主线程退出.
当前线程死亡之后,这个线程中的代码都不会被执行.
在调用此方法之前一定要注意释放之前由C语言框架创建的对象.
六、什么是上下文切换?
现在linux是大多基于抢占式,CPU给每个任务一定的服务时间,当时间片轮转的时候,需要把当前状态保存下来,同时加载下一个任务,这个过程叫做上下文切换。时间片轮转的方式,使得多个任务利用一个CPU执行成为可能,但是保存现场和加载现场,也带来了性能消耗。 那线程上下文切换的次数和时间以及性能消耗如何看呢?
上下文切换的性能消耗在哪里呢? context switch过高,会导致CPU像个搬运工,频繁在寄存器和运行队列直接奔波 ,更多的时间花在了线程切换,而不是真正工作的线程上。直接的消耗包括CPU寄存器需要保存和加载,系统调度器的代码需要执行。间接消耗在于多核cache之间的共享数据。
引起上下文切换的原因有哪些? 对于抢占式操作系统而言, 大体有几种: 1、当前任务的时间片用完之后,系统CPU正常调度下一个任务; 2、当前任务碰到IO阻塞,调度线程将挂起此任务,继续下一个任务; 3、多个任务抢占锁资源,当前任务没有抢到,被调度器挂起,继续下一个任务; 4、用户代码挂起当前任务,让出CPU时间; 5、硬件中断; 监测Linux的应用的时候,当CPU的利用率非常高,但是系统的性能却上不去的时候,不妨监控一下线程/进程的切换,看看是不是context switching导致的overhead过高。 常用命令: pidstat vmstat
七、什么是线程死锁?如何避免死锁?
死锁
当线程A持有独占锁a,并尝试去获取独占锁b的同时,线程B持有独占锁b,并尝试获取独占锁a的情况下,就会发生AB两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。
下面用一个非常简单的死锁示例来帮助你理解死锁的定义。
public class DeadLockDemo {
public static void main(String[] args) {
// 线程a
Thread td1 = new Thread(new Runnable() {
public void run() {
DeadLockDemo.method1();
}
});
// 线程b
Thread td2 = new Thread(new Runnable() {
public void run() {
DeadLockDemo.method2();
}
});
td1.start();
td2.start();
}
public static void method1() {
synchronized (String.class) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程a尝试获取integer.class");
synchronized (Integer.class) {
}
}
}
public static void method2() {
synchronized (Integer.class) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程b尝试获取String.class");
synchronized (String.class) {
}
}
}
}
----------------
线程b尝试获取String.class
线程a尝试获取integer.class
....
...
..
.
无限阻塞下去
如何避免死锁?
教科书般的回答应该是,结合“哲学家就餐“模型,分析并总结出以下死锁的原因,最后得出“避免死锁就是破坏造成死锁的,若干条件中的任意一个”的结论。
造成死锁必须达成的4个条件(原因):
- 互斥条件:一个资源每次只能被一个线程使用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源,在未使用完之前,不能强行剥夺。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
但是,“哲学家就餐”光看名字就很讨厌,然后以上这4个条件看起来也很绕口,再加上笔者又是个懒人,所以要让我在面试时把这些“背诵”出来实在是太难了!必须要想办法把这4个条件简化一下! 于是,通过对4个造成死锁的条件进行逐条分析,我们可以得出以下4个结论。
- 互斥条件 —> 独占锁的特点之一。
- 请求与保持条件 —> 独占锁的特点之一,尝试获取锁时并不会释放已经持有的锁
- 不剥夺条件 —> 独占锁的特点之一。
- 循环等待条件 —> 唯一需要记忆的造成死锁的条件。
不错!复杂的死锁条件经过简化,现在需要记忆的仅只有独占锁与第四个条件而已。
所以,面对如何避免死锁这个问题,我们只需要这样回答! : 在并发程序中,避免了逻辑中出现复数个线程互相持有对方线程所需要的独占锁的的情况,就可以避免死锁。
下面我们通过“破坏”第四个死锁条件,来解决第一个小节中的死锁示例并证明我们的结论。
public class DeadLockDemo2 {
public static void main(String[] args) {
// 线程a
Thread td1 = new Thread(new Runnable() {
public void run() {
DeadLockDemo2.method1();
}
});
// 线程b
Thread td2 = new Thread(new Runnable() {
public void run() {
DeadLockDemo2.method2();
}
});
td1.start();
td2.start();
}
public static void method1() {
synchronized (String.class) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程a尝试获取integer.class");
synchronized (Integer.class) {
System.out.println("线程a获取到integer.class");
}
}
}
public static void method2() {
// 不再获取线程a需要的Integer.class锁。
synchronized (String.class) {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("线程b尝试获取Integer.class");
synchronized (Integer.class) {
System.out.println("线程b获取到Integer.class");
}
}
}
}
-----------------
线程a尝试获取integer.class
线程a获取到integer.class
线程b尝试获取Integer.class
线程b获取到Integer.class
在上面的例子中,由于已经不存在线程a持有线程b需要的锁,而线程b持有线程a需要的锁的逻辑了,所以Demo顺利执行完毕。
总结
是否能够简单明了的在面试中阐述清楚死锁产生的原因,并给出解决死锁的方案,可以体现程序员在面对对并发问题时思路是否清晰,对并发的基础掌握是否牢固等等。 而且在实际项目中并发模块的逻辑往往比本文的示例复杂许多,所以写并发应用之前一定要充分理解本文所总结的要点,并切记,并发程序编程在不显著影响程序性能的情况下,一定要尽可能的保守。
八、说说 sleep() 方法和 wait() 方法区别和共同点?
1.方法来源区别
wait方法定义在Object上,Thread.sleep()定义在Thread上(这很重要,定义决定作用范围)
2.关于锁和cpu
结论:二者都释放cpu,wait()释放锁,Thread.sleep()不会释放锁. 解释如下: 1.别管是Object.wait()还是Thread.sleep(),都是暂停执行,所以这里都会释放cpu. 2.Object.wait()方法是对象拥有,然后对象锁又是在synchronized同步代码块中使用,所以Object.wait()方法拥有锁的控制权,所以他会释放锁资源.而Thread.sleep()是Thread上的静态方法,所以只能使当前线程睡眠,但是它和锁没有任何关系,所以就没有锁的释放这一问题.
3.作用范围
- Object.wait()方法只能在synchronized快中调用,并且需要和notify和notifyAll配合使用.
- Thread.sleep()是可以在任何上下文调用的,注意是暂停当前的线程 所以就方法而言,Object.wait()主要用在多线程之间的协同工作,Thread.sleep()主要是控制一个线程的执行时间长短.
4 关于异常
Object.wait()方法和Thread.sleep()都抛出 InterruptedException,并且方法定义为final, 所以方法不能被重写,那么在使用 该方法时就只能 try()catch(){}异常,(为什么说只能try,因为如果不捕获异常,那么也意味着你的方法抛出的异常就只能是InterruptedException,或者它的子类,所以这里一般都是捕获异常并处理异常,可以在catch中抛出其他异常)
九、synchronized 关键字、volatile 关键字
- volatile是通知jvm当前变量在寄存器或者cpu中的值是不确定的,需要从主存中读取。不会阻塞线程。
- synchronized则是通过锁机制来控制变量是否可以访问。当变量被锁时,其他线程访问变量将被阻塞,直至锁释放。
volatile
- volatile保证其他线程对这个变量操作时是立即可见的,即操作的是从内存中读取的最新值
- 无法保证原子性
- 只能修饰变量
public class Test {
private volatile int count;
public void increase() {
count++;
System.out.println("----" + count);
}
public static void main(String[] args) throws Exception {
Test test = new Test();
for (int i = 0; i < 10; i++) {
new Thread() {
public void run() {
for (int j = 0; j < 10; j++) {
test.increase();
}
};
}.start();
}
}
}
- 控制台输出:
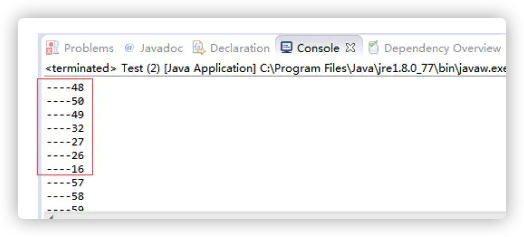
控制台输出
- 使用场景(DCL双重检测锁):
class Singleton{
private volatile static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
if(instance==null) {
synchronized (Singleton.class) {
if(instance==null)
instance = new Singleton();
}
}
return instance;
}
}
synchronized
- 保证原子性
- 即可修饰变量也可修饰方法
- 会阻塞线程
1)synchronized非静态方法
public class Test {
public synchronized void increase1() {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("increase1---->" + i);
}
}
public synchronized void increase2() {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("increase2---->" + i);
}
}
public static void main(String[] args) throws Exception {
Test test = new Test();
new Thread() {
public void run() {
test.increase1();
};
}.start();
new Thread() {
public void run() {
test.increase2();
};
}.start();
}
}
- 控制台输出:
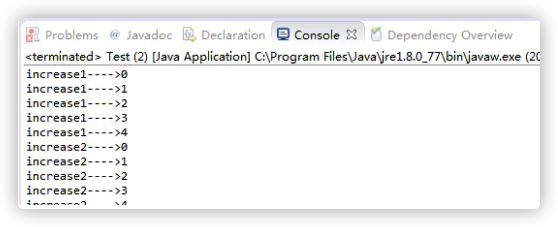
- 结论:
如果一个对象有多个synchronized方法,多个线程同时调用该对象的方法,将会同步执行,即同时只能有一个synchronized方法被调用,其他调用将被阻塞直至该方法执行完
2)synchronized静态方法
懒。。 直接给结论了
synchronized静态方法和非静态方法的区别在于给方法上锁的对象不一样,非静态方法是给调用的对象上锁,静态方法是给类的Class对象上锁
3)synchronized块
public class Test {
public void increase1() {
System.out.println("increase1----------> start");
synchronized (this) {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("increase1---->" + i);
}
}
System.out.println("increase1----------> end");
}
public void increase2() {
System.out.println("increase2----------> start");
synchronized(this) {
for (int i = 0; i < 5; i++) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("increase2---->" + i);
}
}
System.out.println("increase2----------> end");
}
public static void main(String[] args) throws Exception {
Test test = new Test();
new Thread() {
public void run() {
test.increase1();
};
}.start();
new Thread() {
public void run() {
test.increase2();
};
}.start();
}
}
- 控制台输出:
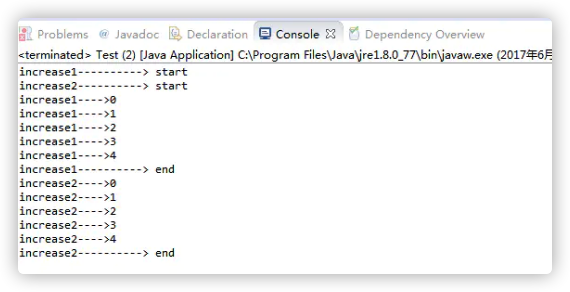
- 结论
synchronized方法是控制同时只能有一个线程执行synchronized方法;synchronized块是控制同时只能有一个线程执行synchronized块中的内容
十、ThreadLocal 有啥用(解决了什么问题)?怎么用?原理了解吗?内存泄露问题了解吗?
ThreadLoacl是什么
在了解ThreadLocal之前,我们先了解下什么是线程封闭
把对象封闭在一个线程里,即使这个对象不是线程安全的,也不会出现并发安全问题。
实现线程封闭大致有三种方式:
- Ad-hoc线程封闭:维护线程封闭性的职责完全由程序来承担,不推荐使用
- 栈封闭:就是用栈(stack)来保证线程安全
public void testThread() {
StringBuilder sb = new StringBuilder();
sb.append("Hello");
}
StringBuilder是线程不安全的,但是它只是个局部变量,局部变量存储在虚拟机栈,虚拟机栈是线程隔离的,所以不会有线程安全问题
- ThreadLocal线程封闭:简单易用
第三种方式就是通过ThreadLocal来实现线程封闭,线程封闭的指导思想是封闭,而不是共享。所以说ThreadLocal是用来解决变量共享的并发安全问题,多少有些不精确。
使用
JDK1.2开始提供的java.lang.ThreadLocal的使用方式非常简单
public class ThreadLocalDemo {
public static void main(String[] args) throws InterruptedException {
final ThreadLocal<String> threadLocal = new ThreadLocal<>();
threadLocal.set("main-thread : Hello");
Thread thread = new Thread(() -> {
// 获取不到主线程设置的值,所以为null
System.out.println(threadLocal.get());
threadLocal.set("sub-thread : World");
System.out.println(threadLocal.get());
});
// 启动子线程
thread.start();
// 让子线程先执行完成,再继续执行主线
thread.join();
// 获取到的是主线程设置的值,而不是子线程设置的
System.out.println(threadLocal.get());
threadLocal.remove();
System.out.println(threadLocal.get());
}
}
运行结果
null
sub-thread : World
main-thread : Hello
null
运行结果说明了ThreadLocal只能获取本线程设置的值,也就是线程封闭。基本上,ThreadLocal对外提供的方法只有三个get()、set(T)、remove()。
原理
使用方式非常简单,所以我们来看看ThreadLocal的源码。ThreadLocal内部定义了一个静态ThreadLocalMap类,ThreadLocalMap内部又定义了一个Entry类,这里只看一些主要的属性和方法
public class ThreadLocal<T> {
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
// 从这里可以看出ThreadLocalMap对象是被Thread类持有的
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}
// 内部类ThreadLocalMap
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
Object value;
// 内部类Entity,实际存储数据的地方
// Entry的key是ThreadLocal对象,不是当前线程ID或者名称
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 注意这里维护的是Entry数组
private Entry[] table;
}
}
根据上面的源码,可以大致画出ThreadLocal在虚拟机内存中的结构
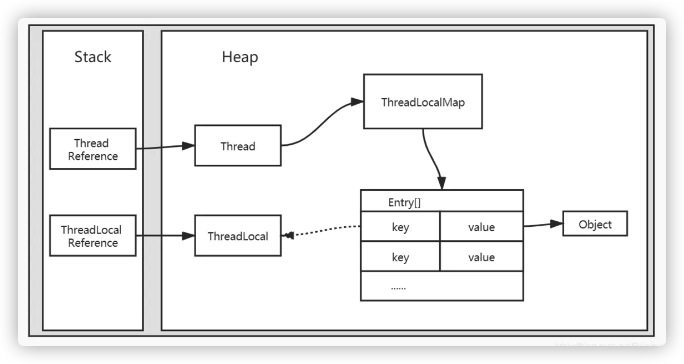
实线箭头表示强引用,虚线箭头表示弱引用。需要注意的是:
- ThreadLocalMap虽然是在ThreadLocal类中定义的,但是实际上被Thread持有。
- Entry的key是(虚引用的)ThreadLocal对象,而不是当前线程ID或者线程名称。
- ThreadLocalMap中持有的是Entry数组,而不是Entry对象。
对于第一点,ThreadLocalMap被Thread持有是为了实现每个线程都有自己独立的ThreadLocalMap对象,以此为基础,做到线程隔离。第二点和第三点理解,我们先来想一个问题,如果同一个线程中定义了多个ThreadLocal对象,内存结构应该是怎样的?此时再来看一下ThreadLocal.set(T)方法:
public void set(T value) {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 根据线程对象获取ThreadLocalMap对象(ThreadLocalMap被Thread持有)
ThreadLocalMap map = getMap(t);
// 如果ThreadLocalMap存在,则直接插入;不存在,则新建ThreadLocalMap
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
也就是说,如果程序定义了多个ThreadLocal,会共用一个ThreadLocalMap对象,所以内存结构应该是这样
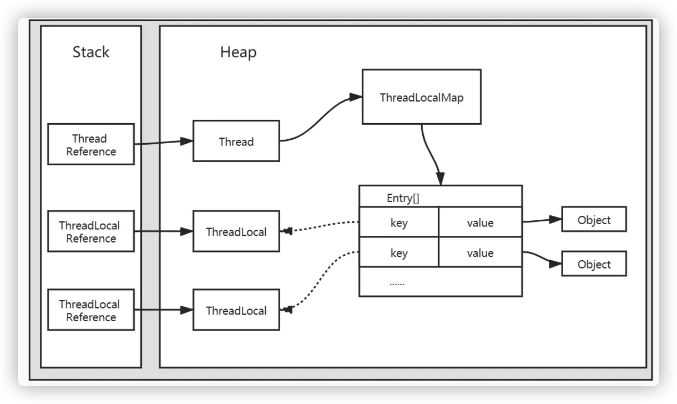
这个内存结构图解释了第二点和第三点。假设Entry中key为当前线程ID或者名称的话,那么程序中定义多个ThreadLocal对象时,Entry数组中的所有Entry的key都一样(或者说只能存一个value)。ThreadLocalMap中持有的是Entry数组,而不是Entry,则是因为程序可定义多个ThreadLocal对象,自然需要一个数组。
内存泄漏
ThreadLocal会发生内存泄漏吗?
会
仔细看下ThreadLocal内存结构就会发现,Entry数组对象通过ThreadLocalMap最终被Thread持有,并且是强引用。也就是说Entry数组对象的生命周期和当前线程一样。即使ThreadLocal对象被回收了,Entry数组对象也不一定被回收,这样就有可能发生内存泄漏。ThreadLocal在设计的时候就提供了一些补救措施:
- Entry的key是弱引用的ThreadLocal对象,很容易被回收,导致key为null(但是value不为null)。所以在调用get()、set(T)、remove()等方法的时候,会自动清理key为null的Entity。
- remove()方法就是用来清理无用对象,防止内存泄漏的。所以每次用完ThreadLocal后需要手动remove()。
有些文章认为是弱引用导致了内存泄漏,其实是不对的。假设把弱引用变成强引用,这样无用的对象key和value都不为null,反而不利于GC,只能通过remove()方法手动清理,或者等待线程结束生命周期。也就是说ThreadLocalMap的生命周期由持有它的线程来决定,线程如果不进入terminated状态,ThreadLocalMap就不会被GC回收,这才是ThreadLocal内存泄露的原因。
应用场景
- 维护JDBC的java.sql.Connection对象,因为每个线程都需要保持特定的Connection对象。
- Web开发时,有些信息需要从controller传到service传到dao,甚至传到util类。看起来非常不优雅,这时便可以使用ThreadLocal来优雅的实现。
- 包括线程不安全的工具类,比如Random、SimpleDateFormat等
与synchronized的关系
有些文章拿ThreadLocal和synchronized比较,其实它们的实现思想不一样。
- synchronized是同一时间最多只有一个线程执行,所以变量只需要存一份,算是一种时间换空间的思想
- ThreadLocal是多个线程互不影响,所以每个线程存一份变量,算是一种空间换时间的思想
总结
ThreadLocal是一种隔离的思想,当一个变量需要进行线程隔离时,就可以考虑使用ThreadLocal来优雅的实现。
十一、为什么要用线程池?ThreadPoolExecutor 类的重要参数了解吗?ThreadPoolExecutor 饱和策略了解吗?线程池原理了解吗?几种常见的线程池了解吗?为什么不推荐使用FixedThreadPool?如何设置线程池的大小?
十二、AQS 了解么?原理?AQS 常用组件:Semaphore (信号量)、CountDownLatch (倒计时器) CyclicBarrier(循环栅栏)
1 AQS 概述
AQS 的全称为(AbstractQueuedSynchronizer),中文即“队列同步器”,这个类放在 java.util.concurrent.locks 包下面。

AQS是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如上篇文章写的ReentrantLock与ReentrantReadWriteLock。除此之外,AQS还能构造出Semaphore,FutureTask(jdk1.7) 等同步器。
2 AQS 原理
2.1 同步队列
AQS 是依赖 CLH 队列锁来完成同步状态的管理。当前线程获取同步状态失败时,同步器会将当前线程以及等待状态等信息构建为一个**节点(Node)**并将其加入同步队列,同步会阻塞当前线程,当同步状态释放时,会将首节点中的线程唤醒,使其再次尝试获取同步状态。
CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(FIFO双向队列)(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
同步队列中的节点(Node)用来保存获取同步状态失败的线程引用、等待状态以及前驱和后继节点信息。
| 属性类型与名称 | 描述 |
|---|---|
| int waitStatus | 等待状态(如CANCELLED=1、SIGNAL=-1、CONDITION=-2、PROPAGATE=-3、INITIAL=0) |
| Node prev | 前驱节点(当节点加入同步队列时被设置,在尾部添加) |
| Node next | 后继节点 |
| Thread thread | 当前获取同步状态的线程 |
节点源码如下:
static final class Node {
// 表示该节点等待模式为共享式,通常记录于nextWaiter,
// 通过判断nextWaiter的值可以判断当前结点是否处于共享模式
static final Node SHARED = new Node();
// 表示节点处于独占式模式,与SHARED相对
static final Node EXCLUSIVE = null;
// waitStatus的不同状态
// 当前结点是因为超时或者中断取消的,进入该状态后将无法恢复
static final int CANCELLED = 1;
// 当前结点的后继结点是(或者将要)由park导致阻塞的,当结点被释放或者取消时,需要通过unpark唤醒后继结点
static final int SIGNAL = -1;
// 表明结点在等待队列中,结点线程等待在Condition上
// 当其他线程对Condition调用了signal()方法时,会将其加入到同步队列中
static final int CONDITION = -2;
// 下一次共享式同步状态的获取将会无条件地向后继结点传播
static final int PROPAGATE = -3;
volatile int waitStatus;
// 记录前驱结点
volatile Node prev;
// 记录后继结点
volatile Node next;
// 记录当前的线程
volatile Thread thread;
// 用于记录共享模式(SHARED), 也可以用来记录CONDITION队列
Node nextWaiter;
// 通过nextWaiter的记录值判断当前结点的模式是否为共享模式
final boolean isShared() { return nextWaiter == SHARED;}
// 获取当前结点的前置结点
final Node predecessor() throws NullPointerException { ... }
// 用于初始化时创建head结点或者创建SHARED结点
Node() {}
// 在addWaiter方法中使用,用于创建一个新的结点
Node(Thread thread, Node mode) {
this.nextWaiter = mode;
this.thread = thread;
}
// 在CONDITION队列中使用该构造函数新建结点
Node(Thread thread, int waitStatus) {
this.waitStatus = waitStatus;
this.thread = thread;
}
}
// 记录头结点
private transient volatile Node head;
// 记录尾结点
private transient volatile Node tail;
节点是构成同步队列的基础,同步器拥有首节点(Head)和尾节点(Tail),没有成功获取同步状态的线程将会成为节点加入该队列的尾部。同步器提供了一个基于CAS的设置尾节点的方法:compareAndSetTail(Node expect, Node update),它需要传递当前线程“认为”的尾节点和当前节点,只有设置成功后,当前节点才正式与之前的尾节点建立关联。

首节点是获取同步状态成功的节点,首节点的线程在释放同步状态时,将会唤醒后继节点,而后继节点将会在获取同步状态成功时将自己设置为首节点。设置首节点是通过获取同步状态成功的线程来完成的,不需要使用CAS来保证,只需将首节点设置成为原首节点的后继节点并断开原首节点的next引用即可。

2.2 同步状态
1) 独占式(EXCLUSIVE)
独占式(EXCLUSIVE)获取需重写tryAcquire、tryRelease方法,并访问acquire、release方法实现相应的功能。
public final void acquire(int arg) {
// 如果线程直接获取成功,或者再尝试获取成功后都是直接工作,
// 如果是从阻塞状态中唤醒开始工作的线程,将当前的线程中断
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// 封装线程,新建结点并加入到同步队列中
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
Node pred = tail;
// 尝试入队, 成功返回
if (pred != null) {
node.prev = pred;
// CAS操作设置队尾
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 通过CAS操作自旋完成node入队操作
enq(node);
return node;
}
// 在同步队列中等待获取同步状态
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// 自旋
for (;;) {
final Node p = node.predecessor();
// 前驱节点是否为头节点&&tryAcquire获取同步状态
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null;
failed = false;
return interrupted;
}
// 获取不到同步状态,将前置结点标为SIGNAL状态并且通过park操作将Node封装的线程阻塞
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
// 如果获取失败,将node标记为CANCELLED
cancelAcquire(node);
}
}
独占式获取同步状态流程:

通过调用同步器的release(int arg)方法可以释放同步状态,该方法在释放了同步状态之后,会唤醒其后继节点(进而使后继节点重新尝试获取同步状态)。
public final boolean release(int arg) {
// 首先尝试释放并更新同步状态
if (tryRelease(arg)) {
Node h = head;
// 检查是否需要唤醒后置结点
if (h != null && h.waitStatus != 0)
// 唤醒后置结点
unparkSuccessor(h);
return true;
}
return false;
}
// 唤醒后继结点
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
// 通过CAS操作将waitStatus更新为0
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
// 检查后置结点,若为空或者状态为CANCELLED,找到后置非CANCELLED结点
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
// 唤醒后继结点
if (s != null)
LockSupport.unpark(s.thread);
}
2)共享式(SHARED)
共享式获取与独占式获取最主要的区别在于同一时刻能否有多个线程同时获取到同步状态。
共享式(SHARED)获取需重写tryAcquireShared、tryReleaseShared方法,并访问acquireShared、releaseShared方法实现相应的功能。与独占式相对,共享式支持多个线程同时获取到同步状态并进行工作,如 Semaphore、CountDownLatch、 CyclicBarrier等。ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
public final void acquireShared(int arg) {
// 尝试共享式获取同步状态,如果成功获取则可以继续执行,否则执行doAcquireShared
if (tryAcquireShared(arg) < 0)
// 以共享式不停得尝试获取同步状态
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
// 向同步队列中新增一个共享式的结点
final Node node = addWaiter(Node.SHARED);
// 标记获取失败状态
boolean failed = true;
try {
// 标记中断状态(若在该过程中被中断是不会响应的,需要手动中断)
boolean interrupted = false;
// 自旋
for (;;) {
// 获取前置结点
final Node p = node.predecessor();
// 若前置结点为头结点
if (p == head) {
// 尝试获取同步状态
int r = tryAcquireShared(arg);
// 若获取到同步状态。
if (r >= 0) {
// 此时,当前结点存储的线程恢复执行,需要将当前结点设置为头结点并且向后传播,
// 通知符合唤醒条件的结点一起恢复执行
setHeadAndPropagate(node, r);
p.next = null;
// 需要中断,中断当前线程
if (interrupted)
selfInterrupt();
// 获取成功
failed = false;
return;
}
}
// 获取同步状态失败,需要进入阻塞状态
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
// 获取失败,CANCELL node
if (failed)
cancelAcquire(node);
}
}
// 将node设置为同步队列的头结点,并且向后通知当前结点的后置结点,完成传播
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head;
setHead(node);
// 向后传播
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if(s == null || s.isShared())
doReleaseShared();
}
}
与独占式一样,共享式获取也需要释放同步状态,通过调用releaseShared(intarg)方法可以释放同步状态,释放同步状态成功后,会唤醒后置结点,并且保证传播性。
public final boolean releaseShared(int arg) {
// 尝试释放同步状态
if (tryReleaseShared(arg)) {
// 成功后唤醒后置结点
doReleaseShared();
return true;
}
return false;
}
// 唤醒后置结点
private void doReleaseShared() {
// 循环的目的是为了防止新结点在该过程中进入同步队列产生的影响,同时要保证CAS操作的完成
for (;;) {
Node h = head;
if (h != null && h != tail) {
int ws = h.waitStatus;
if (ws == Node.SIGNAL) {
if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0))
continue;
unparkSuccessor(h);
}
else if (ws == 0 &&
!compareAndSetWaitStatus(h, 0, Node.PROPAGATE))
continue;
}
if (h == head)
break;
}
}
3)超时获取方式
通过调用同步器的doAcquireNanos(int arg, long nanosTimeout)方法可以超时获取同步状态,即在指定的时间段内获取同步状态,如果获取到同步状态则返回true,否则,返回false。该方法提供了传统Java同步操作(比如synchronized关键字)所不具备的特性。
private boolean doAcquireNanos(int arg, long nanosTimeout)
throws InterruptedException {
if (nanosTimeout <= 0L)
return false;
// 计算超时的时间=当前虚拟机的时间+设置的超时时间
final long deadline = System.nanoTime() + nanosTimeout;
// 调用addWaiter将当前线程封装成独占模式的节点,并且加入到同步队列尾部。
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
// 自旋
for (;;) {
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
// 如果当前节点的前驱节点为头结点,则让当前节点去尝试获取锁。
setHead(node);
p.next = null;
failed = false;
return true;
}
// 如果当前节点的前驱节点不是头结点,或当前节点获取锁失败,
// 则再次判断当前线程是否已经超时。
nanosTimeout = deadline - System.nanoTime();
if (nanosTimeout <= 0L)
return false;
// 调用shouldParkAfterFailedAcquire方法,告诉当前节点的前驱节点,马上进入
// 等待状态了,即做好进入等待状态前的准备。
if (shouldParkAfterFailedAcquire(p, node) &&
nanosTimeout > spinForTimeoutThreshold)
// 调用LockSupport.parkNanos方法,将当前线程设置成超时等待的状态。
LockSupport.parkNanos(this, nanosTimeout);
if (Thread.interrupted())
throw new InterruptedException();
}
} finally {
if (failed)
cancelAcquire(node);
}
}
由上面代码可知,超时获取也是调用addWaiter将当前线程封装成独占模式的节点,并且加入到同步队列尾部。
超时获取与独占式获取同步状态区别在于获取同步状态失败后的处理。如果当前线程获取同步状态失败,则判断是否超时(nanosTimeout小于等于0表示已经超时);如果没有超时,重新计算超时间隔nanosTimeout,然后使当前线程等待nanosTimeout纳秒(当已到设置的超时时间,该线程会从LockSupport.parkNanos(Object blocker, long nanos)方法返回)。
独占式超时获取同步状态流程:

2.3 模板方法
AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
private volatile int state;// 共享变量,使用volatile修饰保证线程可见性
同步状态state通过 protected 类型的getState,setState,compareAndSetState方法进行操作
// 返回同步状态的当前值
protected final int getState() {
return state;
}
// 设置同步状态的值
protected final void setState(int newState) {
state = newState;
}
// CAS更新同步状态,该方法能够保证状态设置的原子性
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
同步器的设计是基于模板方法模式的,也就是说,使用者需要继承同步器并重写指定的方法,随后将同步器组合在自定义同步组件的实现中,并调用同步器提供的模板方法,而这些模板方法将会调用使用者重写的方法。
自定义同步器时需要重写下面几个 AQS 提供的模板方法:
isHeldExclusively()// 该线程是否正在独占资源。只有用到condition才需要去实现它。
tryAcquire(int)// 独占方式。尝试获取资源,成功则返回true,失败则返回false。
tryRelease(int)// 独占方式。尝试释放资源,成功则返回true,失败则返回false。
tryAcquireShared(int)// 共享方式。尝试获取资源。负数表示失败;0表示成功,但没有剩余可用资源;正数表示成功,且有剩余资源。
tryReleaseShared(int)// 共享方式。尝试释放资源,成功则返回true,失败则返回false。
同步器提供的模板方法基本上分为3类:独占式获取与释放同步状态、共享式获取与释放同步状态和查询同步队列中的等待线程情况。
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现tryAcquire-tryRelease、tryAcquireShared-tryReleaseShared中的一种即可。
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 await()函数返回,继续后续动作。
但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如ReentrantReadWriteLock。
下面就来学习几个常用的并发同步工具。
3 Semaphore(信号量)
Semaphore(信号量)用来控制 同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,而Semaphore(信号量)可以指定多个线程同时访问某个资源。
以停车场为例。假设一个停车场只有10个车位,这时如果同时来了15辆车,则只允许其中10辆不受阻碍的进入。剩下的5辆车则必须在入口等待,此后来的车也都不得不在入口处等待。这时,如果有5辆车离开停车场,放入5辆;如果又离开2辆,则又可以放入2辆,如此往复。
在这个停车场系统中,车位即是共享资源,每辆车就好比一个线程,信号量就是空车位的数目。
Semaphore中包含了一个实现了AQS的同步器Sync,以及它的两个子类FairSync和NonFairSync。查看Semaphore类结构:

可见Semaphore也是区分公平模式和非公平模式的。
- 公平模式: 调用 acquire 的顺序就是获取许可证的顺序,遵循 FIFO。
- 非公平模式: 抢占式的。
Semaphore 对应的两个构造方法如下:
public Semaphore(int permits) {
sync = new NonfairSync(permits);
}
public Semaphore(int permits, boolean fair) {
sync = fair ? new FairSync(permits) : new NonfairSync(permits);
}
这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式。
Semaphore实现原理这里就不分析了,可以参考死磕 java同步系列之Semaphore源码解析这篇文章。
需要明白的是,Semaphore也是共享锁的一种实现。它默认构造AQS的state为permits。当执行任务的线程数量超出permits,那么多余的线程将会被放入阻塞队列Park,并自旋判断state是否大于0。只有当state大于0的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执行release方法,release方法使得state的变量会加1,那么自旋的线程便会判断成功。如此,每次只有最多不超过permits数量的线程能自旋成功,便限制了执行任务线程的数量。
Semaphore常用于做流量控制,特别是公用资源有限的应用场景。
| 常用方法 | 描述 |
|---|---|
| acquire()/acquire(int permits) | 获取许可证。获取许可失败,会进入AQS的队列中排队。 |
| tryAcquire()/tryAcquire(int permits) | 获取许可证。获取许可失败,直接返回false。 |
| tryAcquire(long timeout, TimeUnit unit)/ tryAcquire(int permits, long timeout, TimeUnit unit) | 超时等待获取许可证。 |
| release() | 归还许可证。 |
| intavailablePermits() | 返回此信号量中当前可用的许可证数。 |
| intgetQueueLength() | 返回正在等待获取许可证的线程数。 |
| booleanhasQueuedThreads() | 是否有线程正在等待获取许可证。 |
| void reducePermits(int reduction) | 减少reduction个许可证,是个protected方法。 |
| Collection getQueuedThreads() | 返回所有等待获取许可证的线程集合,是个protected方法。 |
使用示例:
public class SemaphoreTest {
private static final int THREAD_COUNT = 50;
public static void main(String[] args) throws InterruptedException {
// 创建一个具有固定线程数量的线程池对象
ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_COUNT);
// 一次只能允许执行的线程数量
final Semaphore semaphore = new Semaphore(10);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
threadPool.execute(() -> {
try {
semaphore.acquire();// 获取1个许可,所以可运行线程数量为10/1=10
test(threadNum);
semaphore.release();// 释放1个许可,所以可运行线程数量为10/1=10
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
threadPool.shutdown();
}
public static void test(int threadNum) throws InterruptedException {
Thread.sleep(1000);// 模拟请求的耗时操作
System.out.println("threadNum:" + threadNum);
Thread.sleep(1000);// 模拟请求的耗时操作
}
}
在代码中,虽然有50个线程在执行,但是只允许10个并发执行。Semaphore的构造方法Semaphore(int permits)接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。
除了 acquire方法之外,另一个比较常用的与之对应的方法是tryAcquire方法,该方法如果获取不到许可就立即返回 false。
4 CountDownLatch (倒计时器)
4.1 概述
在日常开发中经常会遇到需要在主线程中开启多个线程去并行执行任务,并且主线程需要等待所有子线程执行完毕后再进行汇总的场景。jdk 1.5之前一般都使用线程的join()方法来实现这一点,但是join方法不够灵活,难以满足不同场景的需要,所以jdk 1.5之后concurrent包提供了CountDownLatch这个类。
CountDownLatch是一种同步辅助工具,它允许一个或多个线程等待其他线程完成操作。
CountDownLatch是通过一个计数器来实现的,计数器的初始化值为线程的数量。每当一个线程完成了自己的任务后,计数器的值就相应得减1。当计数器到达0时,表示所有的线程都已完成任务,然后在闭锁上等待的线程就可以恢复执行任务。

CountDownLatch的方法:
| 方法 | 描述 |
|---|---|
| await() | 调用该方法的线程等到构造方法传入的 N 减到 0 的时候,才能继续往下执行。 |
| await(long timeout, TimeUnit unit) | 调用该方法的线程等到指定的 timeout 时间后,不管 N 是否减至为 0,都会继续往下执行。 |
| countDown() | 使 CountDownLatch 初始值 N 减 1。 |
| getCount() | 获取当前 CountDownLatch 维护的值,也就是AQS的state的值。 |
CountDownLatch的实现原理,可以查看 【JUC】JDK1.8源码分析之CountDownLatch(五)一文。
根据源码分析可知,CountDownLatch是AQS中共享锁的一种实现。AbstractQueuedSynchronizer中维护了一个volatile类型的整数state,volatile可以保证多线程环境下该变量的修改对每个线程都可见,并且由于该属性为整型,因而对该变量的修改也是原子的。
CountDownLatch默认构造 AQS 的 state 值为 count。创建一个CountDownLatch对象时,所传入的整数N就会赋值给state属性。
当调用countDown()方法时,其实是调用了tryReleaseShared方法以CAS的操作来对state减1;而调用await()方法时,当前线程就会判断state属性是否为0。如果为0,阻塞线程被唤醒继续往下执行;如果不为0,则使当前线程放入阻塞队列Park,直至最后一个线程调用了countDown()方法使得state == 0,再唤醒在await()方法中等待的线程。
特别注意的是:
CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用。如果需要能重置计数,可以使用CyclicBarrier。
4.2 应用场景
CountDownLatch主要应用场景:
- 实现最大的并行性:同时启动多个线程,实现最大程度的并行性。例如110跨栏比赛中,所有运动员准备好起跑姿势,进入到预备状态,等待裁判一声枪响。裁判开了枪,所有运动员才可以开跑。
- 开始执行前等待N个线程完成各自任务:例如一群学生在教室考试,学生们都完成了作答,老师才可以进行收卷操作。
案例:
public class CountDownLatchTest {
private static final int THREAD_COUNT = 30;
public static void main(String[] args) throws InterruptedException {
ExecutorService threadPool = Executors.newFixedThreadPool(10);
final CountDownLatch countDownLatch = new CountDownLatch(THREAD_COUNT);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
threadPool.execute(() -> {
try {
Thread.sleep(1000);// 模拟请求的耗时操作
System.out.println("子线程:" + threadNum);
Thread.sleep(1000);// 模拟请求的耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
countDownLatch.countDown();// 表示一个请求已经被完成
}
});
}
System.out.println("主线程启动...");
countDownLatch.await();
threadPool.shutdown();
System.out.println("子线程执行完毕...");
System.out.println("主线程执行完毕...");
}
}
上面的代码中,我们定义了请求的数量为30,当这 30 个请求被处理完成之后,才会打印子线程执行完毕。
主线程在启动其他线程后调用 CountDownLatch.await() 方法进入阻塞状态,直到其他线程完成各自的任务才被唤醒。
开启的30个线程必须引用闭锁对象,因为他们需要通知 CountDownLatch 对象,他们已经完成了各自的任务。这种通知机制是通过 CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当30个线程都调用了这个方法后,count 的值才等于0,然后主线程就能通过 await()方法,继续执行自己的任务。
5 CyclicBarrier(循环栅栏)
5.1 概述
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。CyclicBarrier 的功能和应用场景与CountDownLatch都非常类似。

CyclicBarrier常用方法:
| 常用方法 | 描述 |
|---|---|
| await() | 在所有线程都已经在此 barrier上并调用 await 方法之前,将一直等待。 |
| await(long timeout, TimeUnit unit) | 所有线程都已经在此屏障上调用 await 方法之前将一直等待,或者超出了指定的等待时间。 |
| getNumberWaiting() | 返回当前在屏障处等待的线程数目。 |
| getParties() | 返回要求启动此 barrier 的线程数目。 |
| isBroken() | 查询此屏障是否处于损坏状态。 |
| reset() | 将屏障重置为其初始状态。 |
5.2 源码分析
构造函数:
// 创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,但它不会在启动 barrier 时执行预定义的操作。
public CyclicBarrier(int parties) {
this(parties, null);
}
// 创建一个新的 CyclicBarrier,它将在给定数量的参与者(线程)处于等待状态时启动,并在启动 barrier 时执行给定的屏障操作。
// 该操作由最后一个进入 barrier 的线程执行。
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
其中,parties 就表示屏障拦截的线程数量。
CyclicBarrier 的最重要的方法就是 await 方法,await() 方法就像树立起一个栅栏的行为一样,将线程挡住了,当拦住的线程数量达到 parties 的值时,栅栏才会打开,线程才得以通过执行。
public int await() throws InterruptedException, BrokenBarrierException {
try {
return dowait(false, 0L);
} catch (TimeoutException toe) {
throw new Error(toe);
}
}
当调用 await() 方法时,实际上调用的是dowait(false, 0L)方法。查看dowait(boolean timed, long nanos):
// 当线程数量或者请求数量达到 count 时 await 之后的方法才会被执行。
private int count;
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
// 获取”独占锁“
lock.lock();
try {
// 保存“当前的generation”
final Generation g = generation;
// 如果当前代损坏,抛出异常
if (g.broken)
throw new BrokenBarrierException();
// 如果线程中断,抛出异常
if (Thread.interrupted()) {
// 将损坏状态设置为 true,并唤醒所有阻塞在此栅栏上的线程
breakBarrier();
throw new InterruptedException();
}
// 将“count计数器”-1
int index = --count;
// 当 count== 0,说明最后一个线程已经到达栅栏
if (index == 0) {
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
// 执行栅栏任务
if (command != null)
command.run();
ranAction = true;
// 将 count 重置为 parties 属性的初始化值
// 唤醒之前等待的线程,并更新generation。
nextGeneration();
// 结束,等价于return index
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// 当前线程一直阻塞,直到“有parties个线程到达barrier” 或 “当前线程被中断” 或 “超时”这3者条件之一发生
// 当前线程才继续执行。
for (;;) {
try {
// 如果没有时间限制,则直接等待,直到被唤醒。
if (!timed)
trip.await();
// 如果有时间限制,则等待指定时间再唤醒(超时等待)。
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
// 当前代没有损坏
if (g == generation && ! g.broken) {
// 让栅栏失效
breakBarrier();
throw ie;
} else {
// 上面条件不满足,说明这个线程不是这代的。
// 就不会影响当前这代栅栏执行逻辑。中断。
Thread.currentThread().interrupt();
}
}
// 如果“当前generation已经损坏”,则抛出异常。
if (g.broken)
throw new BrokenBarrierException();
// 如果“generation已经换代”,则返回index。
if (g != generation)
return index;
// 如果是“超时等待”,并且时间已到,则通过breakBarrier()终止CyclicBarrier
// 唤醒CyclicBarrier中所有等待线程。
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
// 释放“独占锁(lock)”
lock.unlock();
}
}
generation是CyclicBarrier的一个成员变量:
/**
* Generation一代的意思。
* CyclicBarrier是可以循环使用的,用它来标志本代和下一代。
* broken:当前代是否损坏的标志。标志有线程发生了中断,或者异常,就是任务没有完成。
*/
private static class Generation {
boolean broken = false;
}
// 实现独占锁
private final ReentrantLock lock = new ReentrantLock();
// 实现多个线程之间相互等待通知,就是满足某些条件之后,线程才能执行,否则就等待
private final Condition trip = lock.newCondition();
// 初始化时屏障数量
private final int parties;
// 当条件满足(即屏障数量为0)之后,会回调这个Runnable
private final Runnable barrierCommand;
//当前代
private Generation generation = new Generation();
// 剩余的屏障数量count
private int count;
在CyclicBarrier中,同一批的线程属于同一代,即同一个generation;CyclicBarrier中通过generation对象,记录属于哪一代。 当有parties个线程到达barrier,generation就会被更新换代。
总结:
CyclicBarrier内部通过一个 count 变量作为计数器,cout 的初始值为 parties 属性的初始化值,每当一个线程到了栅栏,那么就将计数器减1。如果 count 值为 0 了,表示这是这一代最后一个线程到达栅栏,就会将代更新并重置计数器,并唤醒所有之前等待在栅栏上的线程。- 如果在等待的过程中,线程中断都也会抛出BrokenBarrierException异常,并且这个异常会传播到其他所有的线程,CyclicBarrier会被损坏。
- 如果超出指定的等待时间,当前线程会抛出 TimeoutException 异常,其他线程会抛出BrokenBarrierException异常,CyclicBarrier会被损坏。
5.3 应用场景
CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的应用场景。比如我们用一个 Excel 保存了用户所有银行流水,每个 Sheet 保存一个帐户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个 sheet 里的银行流水,都执行完之后,得到每个 sheet 的日均银行流水,最后,再用 barrierAction 用这些线程的计算结果,计算出整个 Excel 的日均银行流水。
示例 1:
public class CyclicBarrierTest1 {
private static final int THREAD_COUNT = 30;
// 需要同步的线程数量
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
public static void main(String[] args) throws InterruptedException {
// 创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
Thread.sleep(1000);
threadPool.execute(() -> {
System.out.println("childThread:" + threadNum + " is ready");
try {
// 等待60秒,保证子线程完全执行结束
cyclicBarrier.await(60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
System.out.println("childThread:" + threadNum + " is finish");
});
}
threadPool.shutdown();
}
}
运行结果如下:
childThread:0 is ready
childThread:1 is ready
childThread:2 is ready
childThread:3 is ready
childThread:4 is ready
childThread:4 is finish
childThread:0 is finish
childThread:1 is finish
childThread:3 is finish
childThread:2 is finish
childThread:5 is ready
childThread:6 is ready
childThread:7 is ready
childThread:8 is ready
childThread:9 is ready
childThread:9 is finish
childThread:8 is finish
... ...
可以看到当线程数量也就是请求数量达定义的 5 个的时候, await方法之后的方法才被执行。
另外,CyclicBarrier 还提供一个更高级的构造函数CyclicBarrier(int parties, Runnable barrierAction),用于在线程到达屏障时,优先执行barrierAction,方便处理更复杂的业务场景。示例代码如下:
public class CyclicBarrierTest2 {
private static final int THREAD_COUNT = 30;
// 需要同步的线程数量
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
System.out.println("------优先执行------");
});
public static void main(String[] args) throws InterruptedException {
// 创建线程池
ExecutorService threadPool = Executors.newFixedThreadPool(10);
for (int i = 0; i < THREAD_COUNT; i++) {
final int threadNum = i;
Thread.sleep(1000);
threadPool.execute(() -> {
System.out.println("childThread:" + threadNum + " is ready");
try {
// 等待60秒,保证子线程完全执行结束
cyclicBarrier.await(60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
} catch (TimeoutException e) {
e.printStackTrace();
}
System.out.println("childThread:" + threadNum + " is finish");
});
}
threadPool.shutdown();
}
}
运行结果如下:
childThread:0 is ready
childThread:1 is ready
childThread:2 is ready
childThread:3 is ready
childThread:4 is ready
------优先执行------
childThread:4 is finish
childThread:0 is finish
childThread:1 is finish
childThread:3 is finish
childThread:2 is finish
childThread:5 is ready
childThread:6 is ready
childThread:7 is ready
childThread:8 is ready
childThread:9 is ready
------优先执行------
childThread:9 is finish
childThread:6 is finish
... ...
5.4 CyclicBarrier和CountDownLatch的区别
- CountDownLatch的计数器只能使用一次。而CyclicBarrier的计数器可以使用reset()方法重置,可多次使用。
- 侧重点不同。CountDownLatch多用于某一个线程等待若干个其他线程执行完任务之后,它才执行;而CyclicBarrier一般用于多个线程互相等待至一个同步点,然后这些线程再继续一起执行。
- CyclicBarrier还提供其他有用的方法,比如getNumberWaiting方法可以获得Cyclic-Barrier阻塞的线程数量;isBroken()方法用来了解阻塞的线程是否被中断。
十三、ReentrantLock 、 ReentrantReadWriteLock 、StampedLock(JDK8)
JDK8的一种新的读写锁StampedLock
JDK8新增一种新的读写锁StampedLock。一个最重要的功能改进就是读写锁中解决写线程饥饿的问题。
StampedLock与ReentrantReadWriteLock
以StampedLock与ReentrantReadWriteLock两者比较为线索介绍StampedLock锁。关于ReentrantReadWriteLock锁参考文档ReentrantReadWriteLock源码解析。
StampedLock不基于AQS实现
之前包括ReentrantReadWriteLock,ReentrantLock和信号量等同步工具,都是基于AQS同步框架实现的。而在StampedLock中摒弃了AQS框架,为StampedLock实现提供了更多的灵活性。
StampedLock增加乐观读锁机制
先获取记录下当前锁的版本号stamp,执行读取操作后,要验证这个版本号是否改变,如果没有改变继续执行接下来的逻辑。乐观读锁机制基于在系统中大多数时间线程并发竞争不严重,绝大多数读操作都可以在没有竞争的情况下完成的论断。
//乐观读锁
stamp = lock.tryOptimisticRead();
//do some reading
if (lock.validate(stamp)) {
//do somethinng
}
实际中,乐观读的实现是通过判断state的高25位是否有变化来实现的,获取乐观读锁也仅仅是返回当前锁的版本号
public long tryOptimisticRead() {
long s;
return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;
}
StampedLock锁的状态和版本号
基于AQS实现实现的ReentrantReadWriteLock,高16位存储读锁被获取的次数,低16位存储写锁被获取的次数。 而摒弃了AQS的StampedLock,自身维护了一个状态变量state。
private transient volatile long state;
StampedLock的状态变量state被分成3段:
- 高24位存储版本号,只有写锁增加其版本号,而读锁不会增加其版本号;
- 低7位存储读锁被获取的次数;
- 第8位存储写锁被获取的次数,因为只有一位用于表示写锁,所以StampedLock不是可重入锁。
关于状态变量state操作的变量设置:
private static final int LG_READERS = 7; //读线程的个数占有低7位
// Values for lock state and stamp operations
private static final long RUNIT = 1L; //读线程个数每次增加的单位
private static final long WBIT = 1L << LG_READERS;//写线程个数所在的位置 1000 0000
private static final long RBITS = WBIT - 1L;//读线程个数的掩码 111 1111
private static final long RFULL = RBITS - 1L;//最大读线程个数
private static final long ABITS = RBITS | WBIT;//读线程个数和写线程个数的掩码 1111 1111
// Initial value for lock state; avoid failure value zero
//state的初始值。 1 0000 0000,也就是高24位最后一位为1,版本号初始值为1 0000 0000。锁获取失败返回版本号0。
private static final long ORIGIN = WBIT << 1;
StampedLock自旋
如下代码片段,可以看到StampedLock锁获取时存在大量自旋逻辑(for循环)。自旋是一种锁优化技术,在并发程序中大多数的锁持有时间很短暂,通过自旋可以避免线程被阻塞和唤醒产生的开销。 自旋技术对于系统中持有锁时间短暂的任务比较高效,但是对于持有锁时间长的任务是对CPU的浪费。
private long acquireWrite(boolean interruptible, long deadline) {
for (int spins = -1;;) { // spin while enqueuing
....省略代码逻辑....
}
for (int spins = -1;;) {
....省略代码逻辑....
for (int k = spins;;) { // spin at head
....省略代码逻辑....
}
private long acquireRead(boolean interruptible, long deadline) {
for (int spins = -1;;) {
....省略代码逻辑....
for (long m, s, ns;;) {
....省略代码逻辑....
}
....省略代码逻辑....
for (;;) {
....省略代码逻辑....
for (int spins = -1;;) {
for (int k = spins;;) { // spin at head
....省略代码逻辑....
}
StampedLock的CLH队列
StampedLock的CLH队列是一个经过改良的队列,在ReentrantReadWriteLock的等待队列中每个线程节点是依次排队,然后责任链设计模式依次唤醒,这样就可能导致读线程全部唤醒,而写线程处于饥饿状态。StampedLock的等待队列,连续的读线程只有首个节点存储在队列中,其它的节点存储在首个节点的cowait队列中。
StampedLock唤醒读锁是一次性唤醒连续的读锁节点。
类WNode是StampedLock等待队列的节点,cowait存放连续的读线程。
static final class WNode {
volatile WNode prev;
volatile WNode next;
//cowait存放连续的读线程
volatile WNode cowait; // list of linked readers
volatile Thread thread; //non-null while possibly parked
volatile int status; // 0, WAITING, or CANCELLED
final int mode; // RMODE or WMODE
WNode(int m, WNode p) { mode = m; prev = p; }
}
如果两个读节点之间有一个写节点,那么这两个读节点就不是连续的,会分别排队。正是因为这样的机制,会按照到来顺序让先到的写线程先于它后面的读线程执行。
StampedLock只有非公平模式,线程到来就会尝试获取锁。
十四、CAS 了解么?原理?
1、什么是CAS?
CAS:Compare and Swap,即比较再交换。
jdk5增加了并发包java.util.concurrent.*,其下面的类使用CAS算法实现了区别于synchronouse同步锁的一种乐观锁。JDK 5之前Java语言是靠synchronized关键字保证同步的,这是一种独占锁,也是是悲观锁。
2、CAS算法理解
对CAS的理解,CAS是一种无锁算法,CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
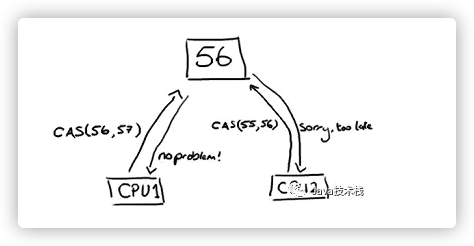
注:t1,t2线程是同时更新同一变量56的值
因为t1和t2线程都同时去访问同一变量56,所以他们会把主内存的值完全拷贝一份到自己的工作内存空间,所以t1和t2线程的预期值都为56。
假设t1在与t2线程竞争中线程t1能去更新变量的值,而其他线程都失败。(失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次发起尝试)。t1线程去更新变量值改为57,然后写到内存中。此时对于t2来说,内存值变为了57,与预期值56不一致,就操作失败了(想改的值不再是原来的值)。
(上图通俗的解释是:CPU去更新一个值,但如果想改的值不再是原来的值,操作就失败,因为很明显,有其它操作先改变了这个值。)
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出 CAS 操作是基于共享数据不会被修改的假设,采用了类似于数据库的commit-retry 的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
3、CAS开销
前面说过了,CAS(比较并交换)是CPU指令级的操作,只有一步原子操作,所以非常快。而且CAS避免了请求操作系统来裁定锁的问题,不用麻烦操作系统,直接在CPU内部就搞定了。但CAS就没有开销了吗?不!有cache miss的情况。这个问题比较复杂,首先需要了解CPU的硬件体系结构:
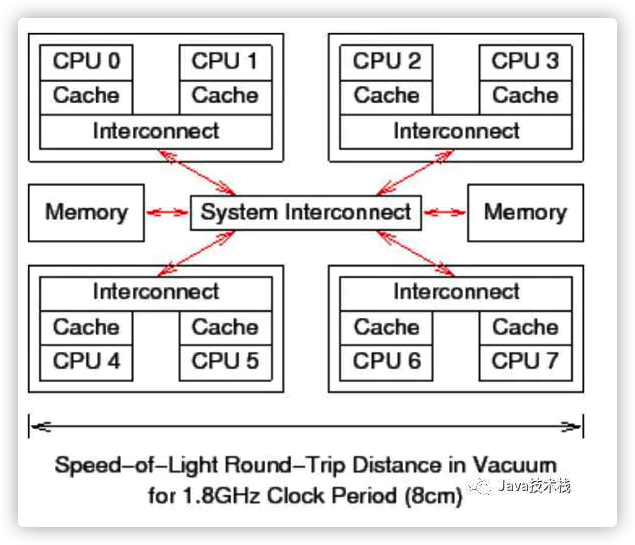
上图可以看到一个8核CPU计算机系统,每个CPU有cache(CPU内部的高速缓存,寄存器),管芯内还带有一个互联模块,使管芯内的两个核可以互相通信。在图中央的系统互联模块可以让四个管芯相互通信,并且将管芯与主存连接起来。数据以“缓存线”为单位在系统中传输,“缓存线”对应于内存中一个 2 的幂大小的字节块,大小通常为 32 到 256 字节之间。当 CPU 从内存中读取一个变量到它的寄存器中时,必须首先将包含了该变量的缓存线读取到 CPU 高速缓存。同样地,CPU 将寄存器中的一个值存储到内存时,不仅必须将包含了该值的缓存线读到 CPU 高速缓存,还必须确保没有其他 CPU 拥有该缓存线的拷贝。
比如,如果 CPU0 在对一个变量执行“比较并交换”(CAS)操作,而该变量所在的缓存线在 CPU7 的高速缓存中,就会发生以下经过简化的事件序列:
CPU0 检查本地高速缓存,没有找到缓存线。
请求被转发到 CPU0 和 CPU1 的互联模块,检查 CPU1 的本地高速缓存,没有找到缓存线。
请求被转发到系统互联模块,检查其他三个管芯,得知缓存线被 CPU6和 CPU7 所在的管芯持有。
请求被转发到 CPU6 和 CPU7 的互联模块,检查这两个 CPU 的高速缓存,在 CPU7 的高速缓存中找到缓存线。
CPU7 将缓存线发送给所属的互联模块,并且刷新自己高速缓存中的缓存线。
CPU6 和 CPU7 的互联模块将缓存线发送给系统互联模块。
系统互联模块将缓存线发送给 CPU0 和 CPU1 的互联模块。
CPU0 和 CPU1 的互联模块将缓存线发送给 CPU0 的高速缓存。
CPU0 现在可以对高速缓存中的变量执行 CAS 操作了
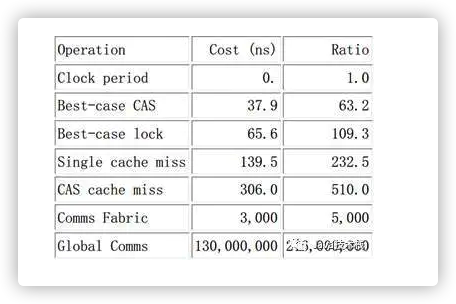
以上是刷新不同CPU缓存的开销。最好情况下的 CAS 操作消耗大概 40 纳秒,超过 60 个时钟周期。这里的“最好情况”是指对某一个变量执行 CAS 操作的 CPU 正好是最后一个操作该变量的CPU,所以对应的缓存线已经在 CPU 的高速缓存中了,类似地,最好情况下的锁操作(一个“round trip 对”包括获取锁和随后的释放锁)消耗超过 60 纳秒,超过 100 个时钟周期。这里的“最好情况”意味着用于表示锁的数据结构已经在获取和释放锁的 CPU 所属的高速缓存中了。锁操作比 CAS 操作更加耗时,是因深入理解并行编程
为锁操作的数据结构中需要两个原子操作。缓存未命中消耗大概 140 纳秒,超过 200 个时钟周期。需要在存储新值时查询变量的旧值的 CAS 操作,消耗大概 300 纳秒,超过 500 个时钟周期。想想这个,在执行一次 CAS 操作的时间里,CPU 可以执行 500 条普通指令。这表明了细粒度锁的局限性。
以下是cache miss cas 和lock的性能对比:
4、CAS算法在JDK中的应用
在原子类变量中,如java.util.concurrent.atomic中的AtomicXXX,都使用了这些底层的JVM支持为数字类型的引用类型提供一种高效的CAS操作,而在java.util.concurrent中的大多数类在实现时都直接或间接的使用了这些原子变量类。
Java 1.7中AtomicInteger.incrementAndGet()的实现源码为:
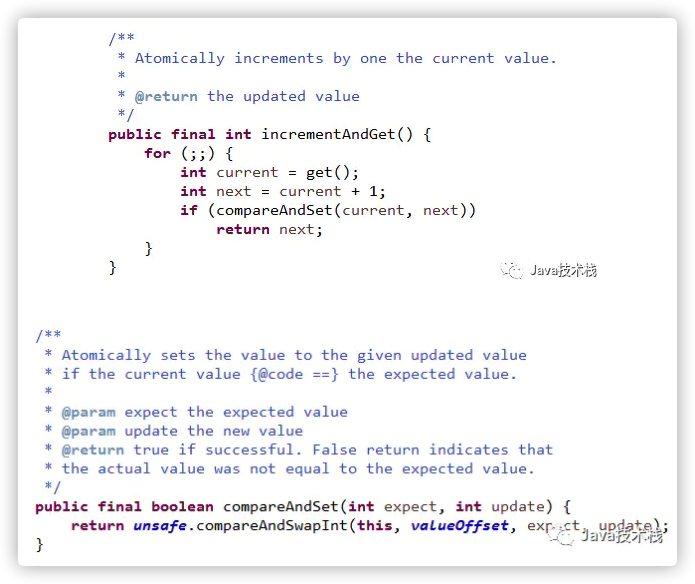
由此可见,AtomicInteger.incrementAndGet的实现用了乐观锁技术,调用了类sun.misc.Unsafe库里面的 CAS算法,用CPU指令来实现无锁自增。所以,AtomicInteger.incrementAndGet的自增比用synchronized的锁效率倍增。
十五、Atomic 原子类
Atomic概览
整个atomic包包含了17个类,如下图所示:根据其功能及其实现原理,可将其分为五个部分。本文主要针对图中序号1都部分进行源码阅读和分析。
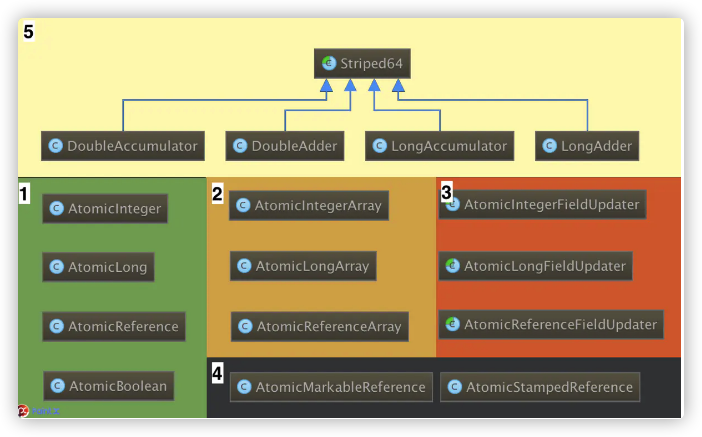
核心对象——Unsafe
整个atomic都是基于Unsafe实现的,Unsafe通过通过单例模式来提供实例对象,这里我们主要关注它提供的几个方法:
# 清单1 sun.misc.Unsafe.class
public final native boolean compareAndSwapInt(Object var1, long var2,
int var4, int var5); // 核心方法CAS
// 参数释义:var1为类对象,参数var2为Field的偏移量,var4为旧值,var5为更新后的值
//(对象和偏移量构成唯一的内存地址,如果对源码JVM有兴趣,可下载源码参考,非本文范畴,不赘述)。
// 计算偏移量
public native long staticFieldOffset(Field var1);
public native long objectFieldOffset(Field var1);
Unsafe提供的大多是native方法,compareAndSwapInt()通过原子的方式将期望值和内存中的值进行对比,如果两者相等,则执行更新操作。
staticFieldOffset()和objectFieldOffset()两方法分别提供两静态、非静态域的偏移量计算方法。
注意:之所以命名为Unsafe,因为该对于大部分Java开发者来说是不安全的,它像C一样,拥有操作指针、分配和回收内存的能力,由该对象申请的内存是无法被JVM回收的,因此轻易别用。当然,如果对并发有非常浓厚的兴趣,就要好好研究下它,许多高性能的框架都使用它作为底层实现,如Netty、Kafka。
AtomicInteger的基本实现
接着再来看AtomicInteger的源码:
# 清单2 AtomicInteger
private static final Unsafe unsafe = Unsafe.getUnsafe(); // 获取单例对象
private static final long valueOffset; // 偏移量
static {
try{
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value")) // 计算偏移量
} catch(Exception ex){ throw new Error(ex);}
}
private volatile int value; // 使用volatile修饰,保证可见性
私有的静态域Unsafe对象和偏移量都是final修饰的,在静态代码块中,通过Unsafe实例计算出域value的偏移地址。 value使用volatile来修饰,保证了其可见性。
# 清单3 getAndSetInt的实现
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2); // 原子获取变量的值
} while(!this.compareAndSwapInt(var1, var2, var5, var4));
// CAS操作,失败重试
return var5;
}
通过方法名可知清单3中的方法getAndSetInt()为获取旧值并赋予新值的操作,通过CAS失败重试的机制来实现原子操作,这就是乐观锁的思想,也是整个并发包的核心思想。
扩展-灵活的函数式编程
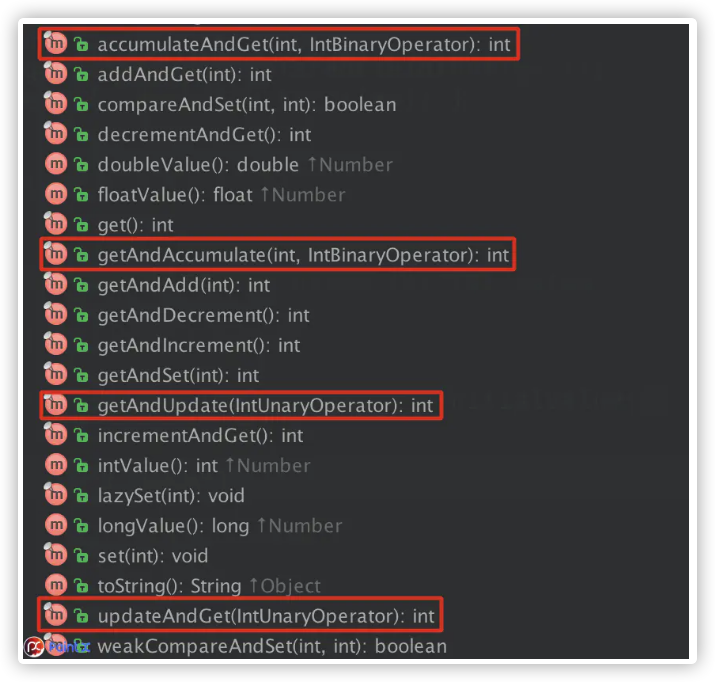
AtomicInteger方法
AtomicInteger的方法中,除了简单的加、减、更新和获取的原子操作外,在JDK1.8中增加了4个方法,即图上标红的方法。通过函数式编程,可以灵活的实现更加复杂的原子操作。
# 清单5 IntUnaryOperator接口
int applyAsInt(int operand);
default IntUnaryOperator compose(IntUnaryOperator before) {
Objects.requireNonNull(before);
return (int v) -> applyAsInt(before.applyAsInt(v));
}
default IntUnaryOperator andThen(IntUnaryOperator after) {
Objects.requireNonNull(after);
return (int t) -> after.applyAsInt(applyAsInt(t));
}
该接口定义了一个待实现方法和两个默认方法,通过compose和andThen即可实现多个IntUnaryOperator的组合调用。在AtomicInteger中做如下调用:
# 清单6 AtomicInteger代码片段
public final int getAndUpdate(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get(); // 获取当前值
next = updateFunction.applyAsInt(prev); // 函数调用计算
} while (!compareAndSet(prev, next)); // CAS更新操作
return prev;
}
如同代码清单7,通过函数式编程,可以轻易地完成复杂计算的原子操作。除了IntUnaryOperator接口,还有一个IntBinaryOperator接口,该接口支持额外增加的参数参与计算,两者有相似之处
# 清单7 IntUnaryOperatorTest
public static void main(String[] args) {
IntOperatorAdd add = new IntOperatorAdd();
IntOperatorMul mul = new IntOperatorMul();
int result = new AtomicInteger(3).updateAndGet(add); // 结果为6 -> 3+3
int result2 = new AtomicInteger(3).updateAndGet(mul); // 结果为9 -> 3*3
int result3 = new AtomicInteger(3).updateAndGet(add.andThen(mul));
// 结果为36 -> 3+3=6, 6*6=36
}
private static class IntOperatorAdd implements IntUnaryOperator {
@Override
public int applyAsInt(int operand) {
return operand + operand;
}
}
private static class IntOperatorMul implements IntUnaryOperator {
@Override
public int applyAsInt(int operand) {
return operand * operand;
}
}
其他原子操作类
除了AtomicInteger外,还有AtomicLong、AtomicReference以及AtomicBoolean三个原子包装类。其实现原理都是一致的,均可举一反三。
十六、并发容器:ConcurrentHashMap 、 CopyOnWriteArrayList 、 ConcurrentLinkedQueue BlockingQueue 、ConcurrentSkipListMap
前言
不考虑多线程并发的情况下,容器类一般使用ArrayList、HashMap等线程不安全的类,效率更高。在并发场景下,常会用到ConcurrentHashMap、ArrayBlockingQueue等线程安全的容器类,虽然牺牲了一些效率,但却得到了安全。
上面提到的线程安全容器都在java.util.concurrent包下,这个包下并发容器不少,今天全部翻出来鼓捣一下。
仅做简单介绍,后续再分别深入探索。
并发容器介绍
- ConcurrentHashMap:并发版HashMap
- CopyOnWriteArrayList:并发版ArrayList
- CopyOnWriteArraySet:并发Set
- ConcurrentLinkedQueue:并发队列(基于链表)
- ConcurrentLinkedDeque:并发队列(基于双向链表)
- ConcurrentSkipListMap:基于跳表的并发Map
- ConcurrentSkipListSet:基于跳表的并发Set
- ArrayBlockingQueue:阻塞队列(基于数组)
- LinkedBlockingQueue:阻塞队列(基于链表)
- LinkedBlockingDeque:阻塞队列(基于双向链表)
- PriorityBlockingQueue:线程安全的优先队列
- SynchronousQueue:读写成对的队列
- LinkedTransferQueue:基于链表的数据交换队列
- DelayQueue:延时队列
1.ConcurrentHashMap 并发版HashMap
最常见的并发容器之一,可以用作并发场景下的缓存。底层依然是哈希表,但在JAVA 8中有了不小的改变,而JAVA 7和JAVA 8都是用的比较多的版本,因此经常会将这两个版本的实现方式做一些比较(比如面试中)。
一个比较大的差异就是,JAVA 7中采用分段锁来减少锁的竞争,JAVA 8中放弃了分段锁,采用CAS(一种乐观锁),同时为了防止哈希冲突严重时退化成链表(冲突时会在该位置生成一个链表,哈希值相同的对象就链在一起),会在链表长度达到阈值(8)后转换成红黑树(比起链表,树的查询效率更稳定)。
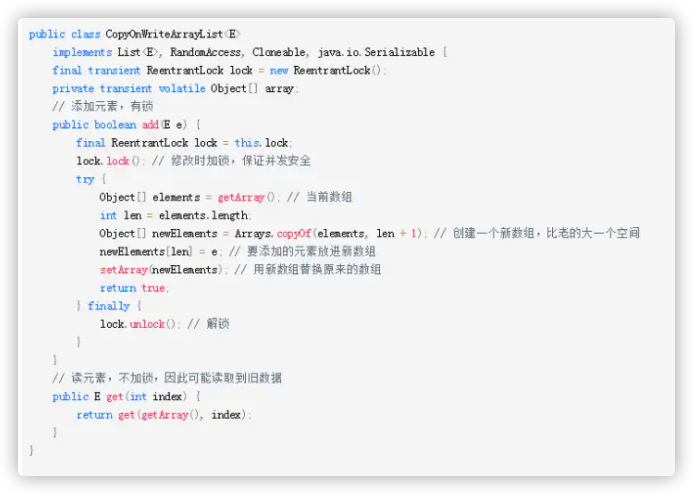
2.CopyOnWriteArrayList 并发版ArrayList
并发版ArrayList,底层结构也是数组,和ArrayList不同之处在于:当新增和删除元素时会创建一个新的数组,在新的数组中增加或者排除指定对象,最后用新增数组替换原来的数组。
适用场景:由于读操作不加锁,写(增、删、改)操作加锁,因此适用于读多写少的场景。
局限:由于读的时候不会加锁(读的效率高,就和普通ArrayList一样),读取的当前副本,因此可能读取到脏数据。如果介意,建议不用。
看看源码感受下:
3.CopyOnWriteArraySet 并发Set
基于CopyOnWriteArrayList实现(内含一个CopyOnWriteArrayList成员变量),也就是说底层是一个数组,意味着每次add都要遍历整个集合才能知道是否存在,不存在时需要插入(加锁)。
适用场景:在CopyOnWriteArrayList适用场景下加一个,集合别太大(全部遍历伤不起)。
4.ConcurrentLinkedQueue 并发队列(基于链表)
基于链表实现的并发队列,使用乐观锁(CAS)保证线程安全。因为数据结构是链表,所以理论上是没有队列大小限制的,也就是说添加数据一定能成功。
5.ConcurrentLinkedDeque 并发队列(基于双向链表)
基于双向链表实现的并发队列,可以分别对头尾进行操作,因此除了先进先出(FIFO),也可以先进后出(FILO),当然先进后出的话应该叫它栈了。
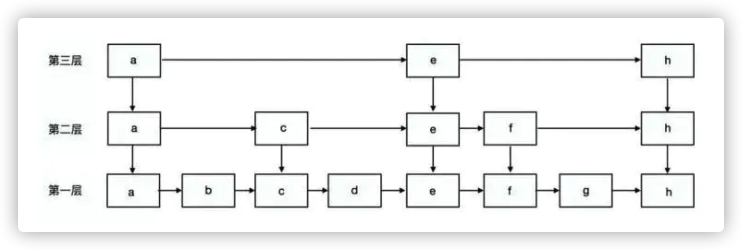
6.ConcurrentSkipListMap 基于跳表的并发Map
SkipList即跳表,跳表是一种空间换时间的数据结构,通过冗余数据,将链表一层一层索引,达到类似二分查找的效果
7.ConcurrentSkipListSet 基于跳表的并发Set
类似HashSet和HashMap的关系,ConcurrentSkipListSet里面就是一个ConcurrentSkipListMap,就不细说了。
8.ArrayBlockingQueue 阻塞队列(基于数组)
基于数组实现的可阻塞队列,构造时必须制定数组大小,往里面放东西时如果数组满了便会阻塞直到有位置(也支持直接返回和超时等待),通过一个锁ReentrantLock保证线程安全。

乍一看会有点疑惑,读和写都是同一个锁,那要是空的时候正好一个读线程来了不会一直阻塞吗?
答案就在notEmpty、notFull里,这两个出自lock的小东西让锁有了类似synchronized + wait + notify的功能。传送门 → 终于搞懂了sleep/wait/notify/notifyAll
9.LinkedBlockingQueue 阻塞队列(基于链表)
基于链表实现的阻塞队列,想比与不阻塞的ConcurrentLinkedQueue,它多了一个容量限制,如果不设置默认为int最大值。
10.LinkedBlockingDeque 阻塞队列(基于双向链表)
类似LinkedBlockingQueue,但提供了双向链表特有的操作。
11.PriorityBlockingQueue 线程安全的优先队列
构造时可以传入一个比较器,可以看做放进去的元素会被排序,然后读取的时候按顺序消费。某些低优先级的元素可能长期无法被消费,因为不断有更高优先级的元素进来。
12.SynchronousQueue 数据同步交换的队列
一个虚假的队列,因为它实际上没有真正用于存储元素的空间,每个插入操作都必须有对应的取出操作,没取出时无法继续放入。
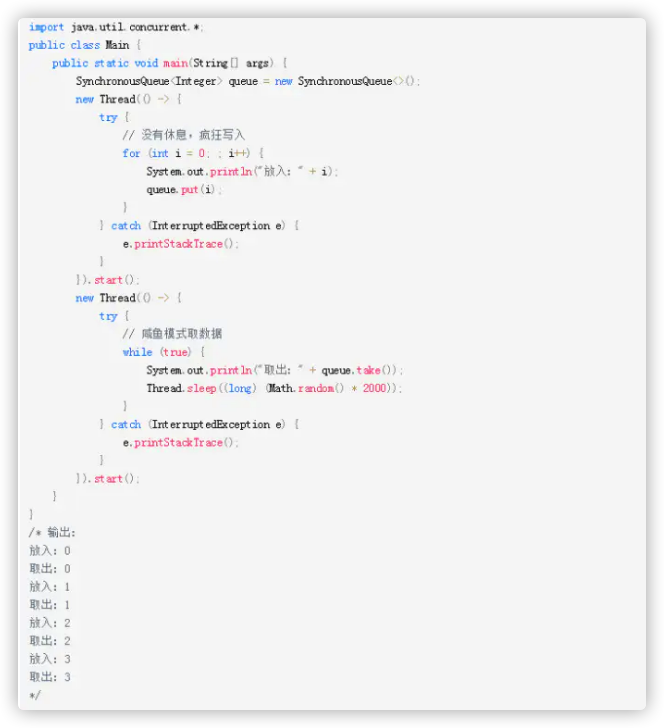
可以看到,写入的线程没有任何sleep,可以说是全力往队列放东西,而读取的线程又很不积极,读一个又sleep一会。输出的结果却是读写操作成对出现。
JAVA中一个使用场景就是Executors.newCachedThreadPool(),创建一个缓存线程池。

13.LinkedTransferQueue 基于链表的数据交换队列
实现了接口TransferQueue,通过transfer方法放入元素时,如果发现有线程在阻塞在取元素,会直接把这个元素给等待线程。如果没有人等着消费,那么会把这个元素放到队列尾部,并且此方法阻塞直到有人读取这个元素。和SynchronousQueue有点像,但比它更强大。
14.DelayQueue 延时队列
可以使放入队列的元素在指定的延时后才被消费者取出,元素需要实现Delayed接口。
总结
上面简单介绍了JAVA并发包下的一些容器类,知道有这些东西,遇到合适的场景时就能想起有个现成的东西可以用了。想要知其所以然,后续还得再深入探索一番。
十七、Future 和 CompletableFuture
CompletableFuture是java 8引入的,用于Java异步编程。异步编程是一种通过在与主应用程序线程不同的线程上运行任务并通知主线程其进度,完成或失败的方法来编写非阻塞代码的方法。 这样,您的主线程就不会阻塞/等待任务完成,并且可以并行执行其他任务。具有这种并行性可以大大提高程序的性能。
Future
Future被用作异步计算结果的参考。它提供了一个isDone()方法来检查计算是否完成,以及一个get()方法来检索计算完成后的结果。
Future VS CompletableFuture:
1.手动完成
Future提供了一个isDone()方法来检查计算是否完成,以及get()方法来检索计算结果。但是,Future不提供手动完成的方法。CompletableFuture的complete()方法可帮助我们手动完成Future
/**
* Manual Completion 手动完成
*/
private static void manualCompletion() throws ExecutionException, InterruptedException {
ExecutorService executorService = Executors.newSingleThreadExecutor();
CompletableFuture<String> future = CompletableFuture.supplyAsync(()->{
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "1111";
});
executorService.submit(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//手动结束核心
future.complete("手动完成");
});
System.out.println(future.get());
executorService.shutdown();
}
因为Future的get()方法在完成计算的之前是阻塞的,我们可以使用complete()方法来手动完成计算。
2.多个Future组成调用链
/**
* 调用链
*/
public static void callbackChain() throws ExecutionException, InterruptedException {
CompletableFuture completableFuture
= CompletableFuture
.supplyAsync(() -> "Knolders!")
.thenRun(() -> System.out.println("Example with thenRun()."));
System.out.println(completableFuture.get());
}
3.组合多个CompletableFuture结果
如果是Future,则无法创建异步工作流程,即长时间运行的计算。但是CompletableFuture为我们提供了方法来实现此功能:
/**
* 组合
*/
private static void thenCompose() {
CompletableFuture<String> completableFuture =
CompletableFuture.supplyAsync(() -> "Hello")
.thenCompose(value ->
CompletableFuture.supplyAsync(
() -> value + " Knolders! Its thenCompose"));
completableFuture.thenAccept(System.out::println); // Hello Knolders! Its thenCompose
}
如果你希望合并要并行运行的100种不同的Future,然后在所有这些Future完成后再运行某些功能。可是使用如下方法:
/**
* 组合所有的结果
*/
private static void allOf() throws ExecutionException, InterruptedException {
CompletableFuture<String> completableFuture1
= CompletableFuture.supplyAsync(() -> "Hello");
CompletableFuture<String> completableFuture2
= CompletableFuture.supplyAsync(() -> "lv!");
CompletableFuture<String> completableFuture3
= CompletableFuture.supplyAsync(() -> "Its allOf");
/*
这个方法并不直接返回结果只是返回一个CompletableFuture
*/
CompletableFuture<Void> combinedFuture
= CompletableFuture.allOf(completableFuture1, completableFuture2, completableFuture3);
System.out.println(combinedFuture.get()); //输出null
assert (completableFuture1.isDone());
assert (completableFuture2.isDone());
assert (completableFuture3.isDone());
//使用以下两种方法获取最终结果
CompletableFuture<List<String>> listCompletableFuture = combinedFuture.thenApply(v ->
Stream.of(completableFuture1, completableFuture2, completableFuture3).
map(CompletableFuture::join).
collect(Collectors.toList()));
System.out.println(listCompletableFuture.get());
String combined = Stream.of(completableFuture1, completableFuture2, completableFuture3)
.map(CompletableFuture::join)
.collect(Collectors.joining(" "));
System.out.println(combined);
}
4.异常处理
如果发生异常,调用链将会停止调用。
private static void exception() {
Integer age = -1;
CompletableFuture<String> exceptionFuture = CompletableFuture.supplyAsync(() -> {
if (age < 0) {
throw new IllegalArgumentException("Age can not be negative");
}
if (age > 18) {
return "Adult";
} else {
return "Child";
}
}).exceptionally(ex -> {
System.out.println("Oops! We have an exception - " + ex.getMessage());
return "Unknown!";
});
exceptionFuture.thenAccept(System.out::println); //Unknown!
}
private static void exceptionUsingHandle() {
Integer age = -1;
CompletableFuture<String> exceptionFuture = CompletableFuture.supplyAsync(() -> {
if (age < 0) {
throw new IllegalArgumentException("Age can not be negative");
}
if (age > 18) {
return "Adult";
} else {
return "Child";
}
}).handle((result, ex) -> {
if (ex != null) {
System.out.println("Oops! We have an exception - " + ex.getMessage());
return "Unknown!";
}
return result;
});
exceptionFuture.thenAccept(System.out::println); // Unknown!
}
十八、……
JVM
对于 Java 程序员来说,JVM 帮助我们做了很多事情比如内存管理、垃圾回收等等。在 JVM 的帮助下,我们的程序出现内存泄漏这些问题的概率相对来说是比较低的。但是,这并不代表我们在日常开发工作中不会遇到。万一你在工作中遇到了 OOM 问题,你至少要知道如何去排查和解决问题吧! 并且,就单纯从面试角度来说,JVM 是 Java 后端面试(大厂)中非常重要的一环。不论是应届还是社招,面试国内的一些大厂,你都会被问到很多 JVM 相关的问题(应届的话侧重理论,社招实践)。
只有搞懂了 JVM 才有可能真正把 Java 语言“吃透”。学习 JVM 这部分的内容,一定要注意要实战和理论结合。
书籍的话,《深入理解 Java 虚拟机》 这本书是首先要推荐的。
下面是我总结的一些关于 JVM 的小问题,你可以拿来自测:
一、什么是虚拟机?
1、 什么是JVM?
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机包括一套字节码指令集、一组寄存器、一个栈、一个垃圾回收堆和一个存储方法域。 JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM在执行字节码时,实际上最终还是把字节码解释成具体平台上的机器指令执行。
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。这就是Java的能够“一次编译,到处运行”的原因。
2、JRE/JDK/JVM是什么关系?
JRE(JavaRuntimeEnvironment,Java运行环境),也就是Java平台。所有的Java 程序都要在JRE下才能运行。普通用户只需要运行已开发好的java程序,安装JRE即可。
JDK(Java Development Kit)是程序开发者用来来编译、调试java程序用的开发工具包。JDK的工具也是Java程序,也需要JRE才能运行。为了保持JDK的独立性和完整性,在JDK的安装过程中,JRE也是 安装的一部分。所以,在JDK的安装目录下有一个名为jre的目录,用于存放JRE文件。
JVM(JavaVirtualMachine,Java虚拟机)是JRE的一部分。它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。JVM有自己完善的硬件架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。
3、JVM原理
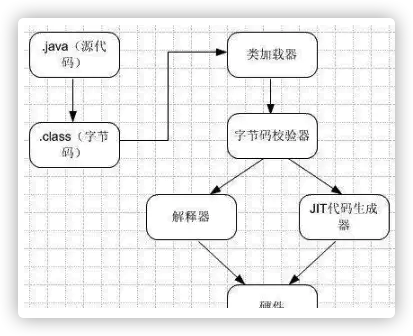
Java编译器只要面向JVM,生成JVM能理解的代码或字节码文件。Java源文件经编译成字节码程序,通过JVM将每一条指令翻译成不同平台机器码,通过特定平台运行。
我刚整理了一套2018最新的0基础入门和进阶教程,无私分享,加Java学习裙 :678-241-563 即可获取,内附:开发工具和安装包,以及系统学习路线图
4、JVM的体系结构
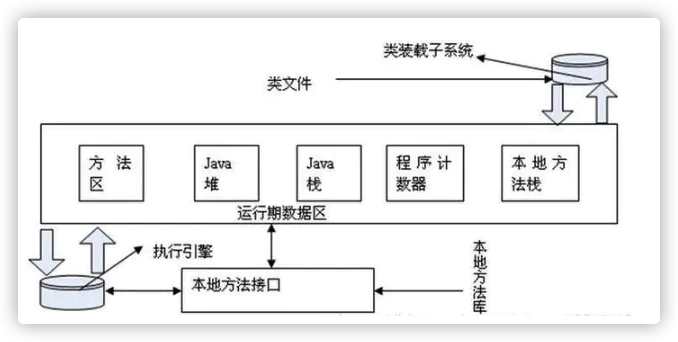
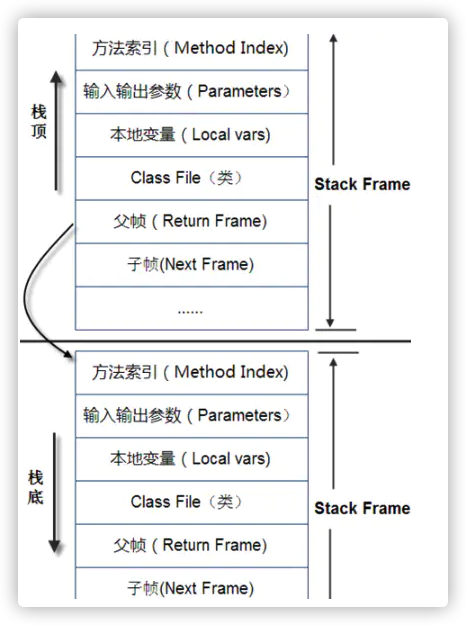
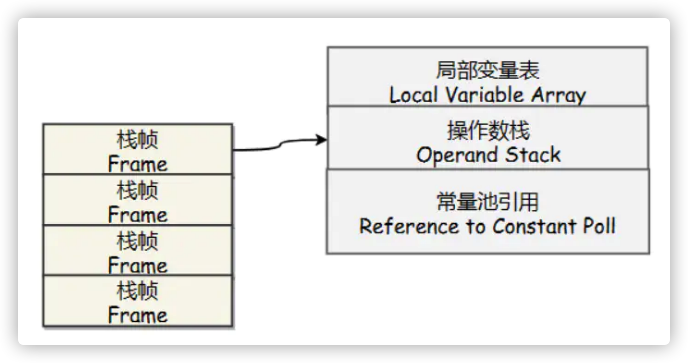
(1)java栈内存,它等价于C语言中的栈, 栈的内存地址是不连续的, 每个线程都拥有自己的栈。 栈里面存储着的是StackFrame,在《JVM Specification》中文版中被译作java虚拟机框架,也叫做栈帧。StackFrame包含三类信息:局部变量,执行环境,操作数栈。局部变量用来存储一个类的方法中所用到的局部变量。执行环境用于保存解析器对于java字节码进行解释过程中需要的信息,包括:上次调用的方法、局部变量指针和 操作数栈的栈顶和栈底指针。操作数栈用于存储运算所需要的操作数和结果。StackFrame在方法被调用时创建,在某个线程中,某个时间点上,只有一个 框架是活跃的,该框架被称为Current Frame,而框架中的方法被称为Current Method,其中定义的类为Current Class。局部变量和操作数栈上的操作总是引用当前框架。当Stack Frame中方法被执行完之后,或者调用别的StackFrame中的方法时,则当前栈变为另外一个StackFrame。Stack的大小是由两种类 型,固定和动态的,动态类型的栈可以按照线程的需要分配。 下面两张图是关于栈之间关系以及栈和非堆内存的关系基本描述:
(2) Java堆是用来存放对象信息的,和Stack不同,Stack代表着一种运行时的状态。换句话说,栈是运行时单位,解决程序该如何执行的问题,而堆是存储的单位, 解决数据存储的问题。Heap是伴随着JVM的启动而创建,负责存储所有对象实例和数组的。堆的存储空间和栈一样是不需要连续的。
(3)程序计数寄存器,程序计数器(Program Counter Register)是一块较小的内存空间,它的作用可以看做是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java 虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间的计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。如果线程正在执行的是一个Java 方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Natvie 方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在Java 虚拟机规范中没有规定任何OutOfMemoryError 情况的区域。
(4)方法区域(Method Area),在Sun JDK中这块区域对应的为PermanetGeneration,又称为持久代。方法区域存放了所加载的类的信息(名称、修饰符等)、类中的静态变量、类中定义为final类型的常量、类中的Field信息、类中的方法信息,当开发人员在程序中通过Class对象中的getName、isInterface等方法来获取信息时,这些数据都来源于方法区域,同时方法区域也是全局共享的,在一定的条件下它也会被GC,当方法区域需要使用的内存超过其允许的大小时,会抛出OutOfMemory的错误信息。
(5)运行时常量池(Runtime Constant Pool),存放的为类中的固定的常量信息、方法和Field的引用信息等,其空间从方法区域中分配。
(6)本地方法堆栈(Native Method Stacks),JVM采用本地方法堆栈来支持native方法的执行,此区域用于存储每个native方法调用的状态。
二、Java 内存区域是怎么划分的?大对象放在哪个内存区域?
一、运行时数据区域
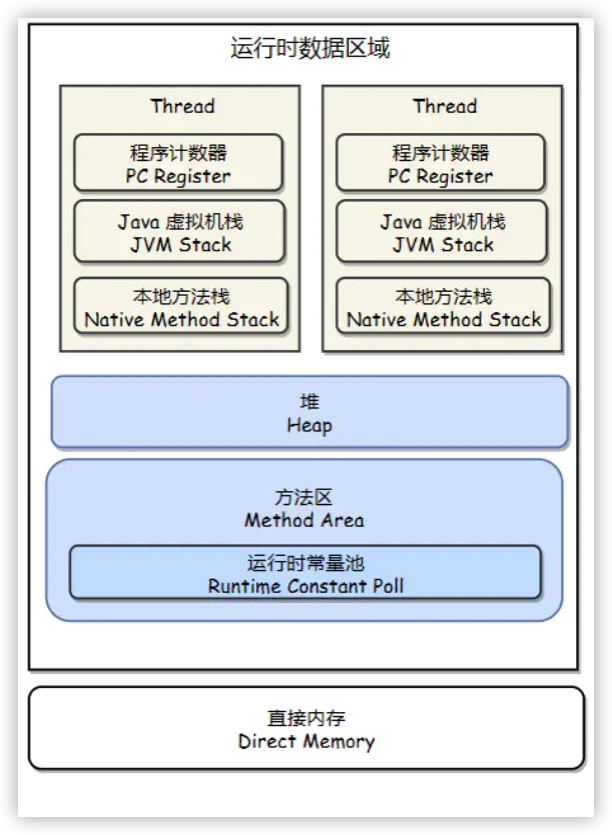
程序计数器
记录正在执行的虚拟机字节码指令地址(如果正在执行的是本地的方法则为空)。
虚拟机栈
每个Java方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在Java虚拟机栈中入栈和出栈的过程。
可以通过-Xss这个虚拟机参数来指定一个Java虚拟机栈内存大小:
java -Xss = 512M HackTheJava
该区域可能抛出以下异常: 1、当线程请求的栈深度超过最大值,会抛出StackOverflowError异常; 2、栈进行动态扩展时如果无法申请到足够内存,会抛出OutOfMemoryError异常。
本地方法栈
本地方法不是用Java实现,对待这些方法需要特别处理。 与Java虚拟机栈类似,它们之间的区别只不过是本地方法栈为本地方法服务。
堆
所有对象实例都在这里分配内存。
是垃圾收集器的主要区域(“GC堆”),现代的垃圾收集器基本都是采用分代收集算法,该算法的思想是针对不同的对象采取不同的垃圾回收算法,因此虚拟机把Java堆分成以下三块:
- 新生代(Young Generation)
- 老年代(Tenured Generation)
- 永久代(Permanent Generation)
当一个对象被创建时,首先进入新生代,之后有可能被转移到老年代中。新生代存放着大量的生命很短的对象,因此新生代在三个区域中垃圾回收的频率最高。为了更高效率地进行垃圾回收,把新生代分成以下三个空间:
- Eden
- From Survivor
- To Survivor
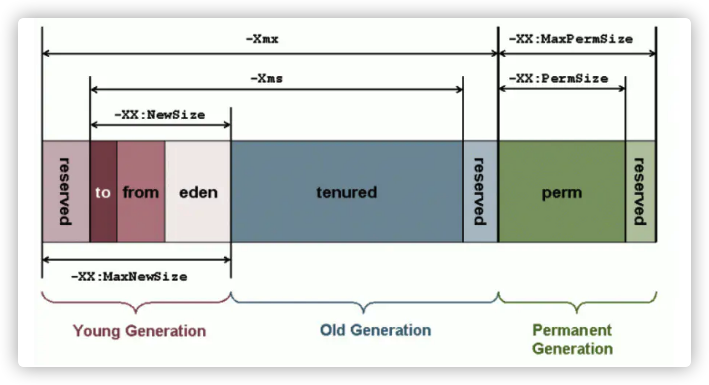
Java堆不需要连续内存,并且可以动态增加其内存,增加失败会抛出OutOfMenmoryError异常。 可以通过-Xms和-Xmx两个虚拟机参数来指定一个程序的Java堆内存大小,第一个参数设置初始值,第二个参数设置最大值。
java -Xms = 1M -Xmx = 2M HackTheJava
方法区
用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。 和Java堆不一样不需要连续的内存,并且可以动态扩展,动态扩展失败一样会抛出OutOfMemoryError异常。 对这块区域进行垃圾回收的主要目标是对常量池的回收和类的卸载,但是一般比较难实现,HotSpot把它当成永久代来进行垃圾回收。
运行常量池
运行常量池是方法区的一部分。 Class文件中的常量池(编译器生成的各种字面量和符号引用)会在类加载后被放入这个区域。 除了在编译期生成的常量,还允许动态生成,例如String类的intern()。这部分常量也会被放入运行时常量池。
直接内存
在 JDK 1.4 中新加入了 NIO 类,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在 Java 堆里的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在 Java 堆和 Native 堆中来回复制数据。
二、垃圾收集
重拾Markdown,一些用法的使用记录
1、空行
起作用的:正文内容。 不起作用的:各级标题、分隔线、代码框编辑前后。使用前后都添加空行
2、缩进控制
缩进一个空格。
缩进两个空格。
https://www.jianshu.com/p/9d94660a96f1
3、代码展示

```和`两者包含的代码框有什么不同?
```代码框。
`代码片。
https://www.jianshu.com/p/b9b582bb6760
4、Markdown是否有转义字符的使用?
比如代码框符号```,引用符号>等。这个转义字符就是反斜杠 \。 https://www.jianshu.com/p/b9b582bb6760
5、简数编辑区域的Markdown怎么设置图片的位置?
暂时没有解决。
6、一些说明:
**图片连接地址前后都设置一个空行。**简书的markdown文章中的图片不用做其他设置都是默认居中,而在个人博客中却默认左对齐,具体效果如下图。对于有轻微强迫症的笔者决定将所有图片修改为居中对齐,搜索了一下,只需在markdown文件中的图片引用前后加上 HTML
-----空行----
<div align=center>
![]()
</div>
-----空行----
http://www.php-master.com/post/68996.html
7、强制换行
markdown编辑器下直接回车,预览时换行是显示不了的。这时就需要强制换行了。
强制换行语法:<br>。可以直接使用,在简书编辑区域同样有效。
8、杂
<br>与<br/>?
不同的标准下的产物,使用上没什么差异,相互兼容。
分隔符还是统一使用***;使用—如果它的上面没有空行,文字将会被误解析成标题。
Markdown编辑的文本在不同的解析器下面,换行的长度会不同。
三、垃圾回收有哪些算法?GC 的流程
导读
1、一个对象一生经历了什么? 2、如何判断对象是否可用? 3、引用计数法和可达性分析算法各自优缺点? 4、哪些对象可以作为GC ROOT? 5、垃圾回收的时候如何快速寻找根节点? 6、垃圾回收算法有哪些?各自优缺点? 7、有哪些垃圾回收器?各自优缺点?适用什么场景?
1、对象回收处理过程
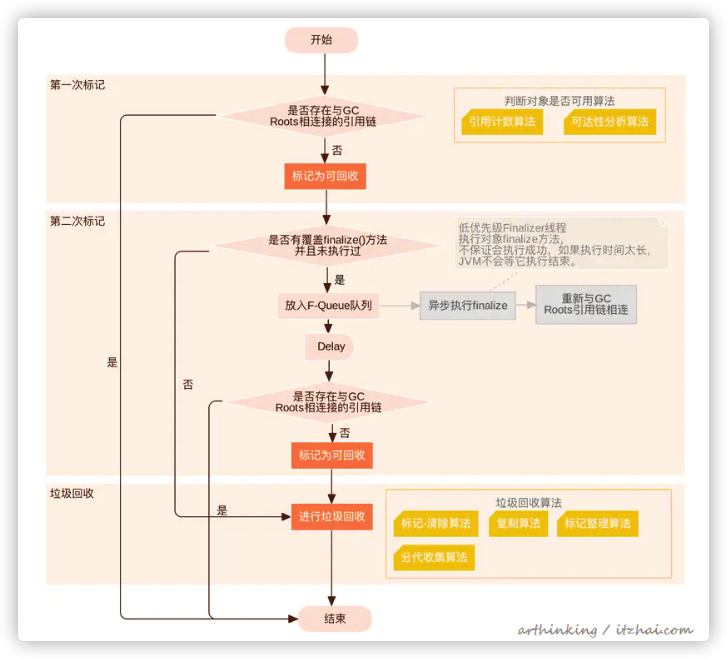
2、判断用户是否可用计算
2.1、引用计数算法
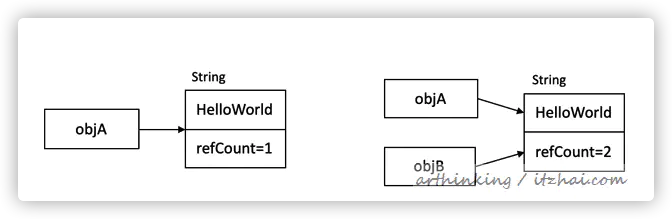
如上图,给对象一个引用技术refCount。每有一个对象引用它,计时器加1,当它为0时,表示对象补课在用。
缺点。
很难解决循环引用的问题。
objA.instance = objB
objB.instance = objA
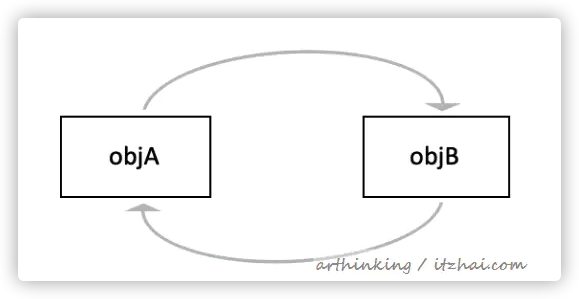
如上,即使objA和objB 都不在被访问后,但是它们还在 相互引用,所以计数器不会为0
2.2、可达性分析算法
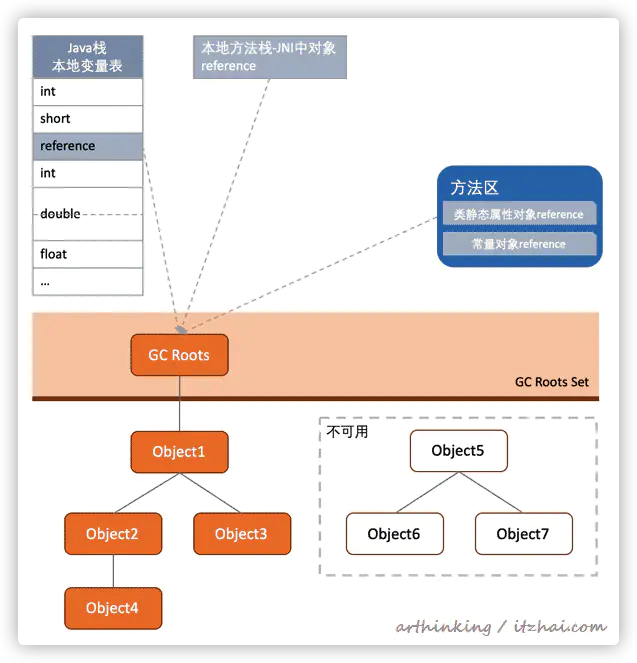
如上图,从GC Roots开始向下搜索,连接的路径为引用链;
GC Roots不可达的对象被判为不可用; 可作为GC Root的对象
如上图,虚拟机栈帧中本地变量表引用的对象,本地方法栈中,JNI引用的对象,方法区中的类静态属性引入的对象和常量引用对象都可以作为GC Root。
引用类型
- 强引用: 类似 object a = new object();
- 软引用:
SoftReference
ref = new SoftReference (“Hello World”);OOM前,JVM会把这些对象列入回收范围进行二次回收,如果回收后内存还是不做,则OOM。 - 弱引用:
WeakReference
weakCar = new WeakReference (car);每次垃圾收集,弱引用的对象就会被清理 - 虚引用: 幽灵引用,不能用来获取一个对象的实例,唯一用途:当一个虚引用引用的对象被回收,系统会收到这个对象被回收的通知。
3、HotSpot中如何实现判断是否存在与GC Roots相连接的引用链

第一小节流程图里的是否存在与GC Roots相连接的引用链 这个判断子流程是怎么实现的呢,这节我们来仔细探讨下。
一般的,我们都是选取可达性分析算法,这里主要阐述怎么寻找GC Root以及如何检查引用链。
3.1、枚举根节点
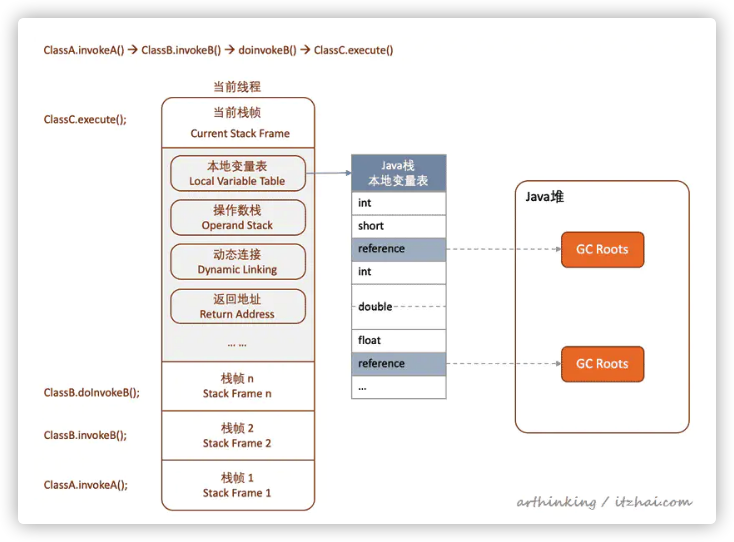
如上图,在一个调用关系为:
ClassA.invokeA() –> ClassB.invokeB() –>doinvokeB() –>ClassC.execute()
的情况下,每个调用对应一个栈帧,栈帧里面的本地变量表存储了GC Roots的引用。
如果直接遍历所有的栈去查找GC Roots,效率太低了。为此我们引入了OopMap和安全点的概念。
安全点和OopMap
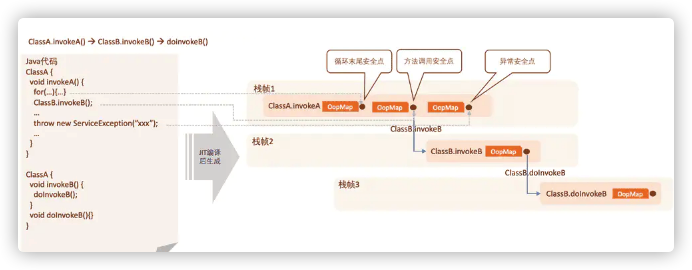
如上图,在源代码编译的时候,会在特定位置下记录安全点,一般为:
1、循环的末尾
2、方法返回前 或者调用方法的call指令后
3、可能抛出异常的位置
通过安全点把代码分成几段,每段代码一个OopMap。
OopMap记录栈上本地变量到堆上对象的引用关系,每当触发GC的时候,程序都先跑的最近的安全点,然后自动挂起,然后在触发更新OopMap,然后进行枚举类GC ROOT,进行垃圾回收:
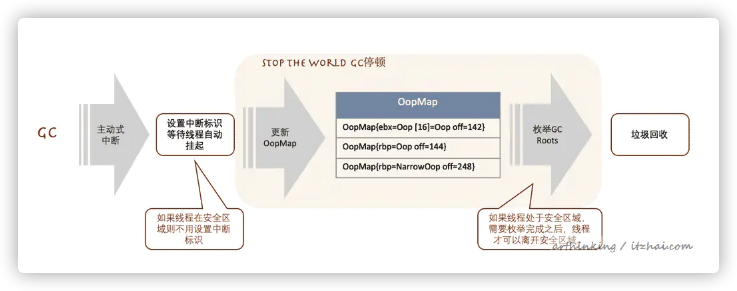
安全区域:在一段代码片段之中,引用关系不会发生变化,因此在这个区域中的任意位置开始 GC 都是安全的。如处于Sleep或者Blocked状态的线程。
为了在枚举GC Roots的过程中,对象的引用关系不会变更,所以需要一个GC停顿。
还有一种抢先式中断的方式,几乎没有虚拟机采用:先中断所有线程,发现线程没中断在安全点,恢复它,继续执行到安全点。
找到了该回收的对象,下一步就是清掉这些对象了,HotSpot将去交给CG收集器。
4、垃圾回收算法
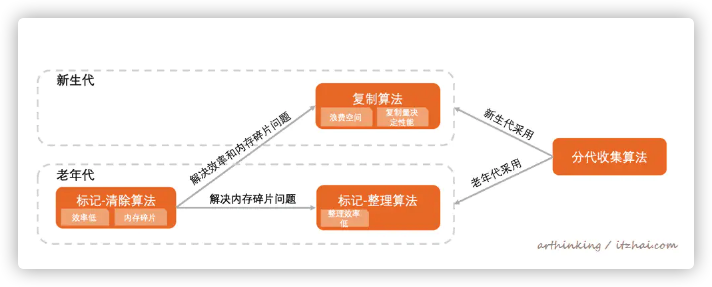
概览图
4.1、标记-清除算法
4.1.1、算法描述
标记阶段:标记处所有需要回收的对象;
清除阶段:标记成功后,统一回收所有被标记的对象;

4.1.2、不足
效率不高:标记和清除两个过程效率都不高;
空间问题:产生大量不连续的内存碎片,进而无法容纳大对象提早触发另一次GC.。
4.2、复制算法
4.2.1、算法描述
将可用内存分为容量大小相等的两块,每次只使用其中一块;
当一块用完,就将存活着的对象复制到另一块,然后将这块全部内存清理掉;
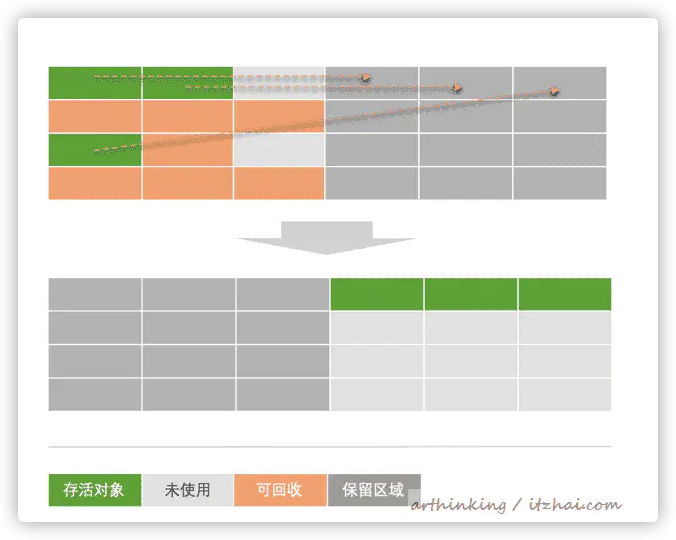
4.2.2、优点
不会产生不连续的内存碎片
提高效率:
回收:每次都是对整个半区进行回收;
分配:分配时也不用考虑内存碎片的问题,只要移动指针,按顺序分配内存即可。
4.2.3、缺点
可用内存缩小为原来的一半了,适合GC过后只有少量存活的新生代,可以根据实际情况,将内存块大小比例适当调整;
如果存活对象数量比较大,复制性能会变得很差。
4.2.4、JVM中新生代的垃圾回收
如下图,分为新生代和老年代。其中新生代又分为一个Eden区和两个Survivor去(from区和to区),默认Eden : from : to 比例为8:1:1。
可通过JVM参数:-XX:SurvivorRatio配置比例,-XX:SurvivorRatio=8 表示 Eden区大小 / 1块Survivor区大小 = 8。
第一次Young GC
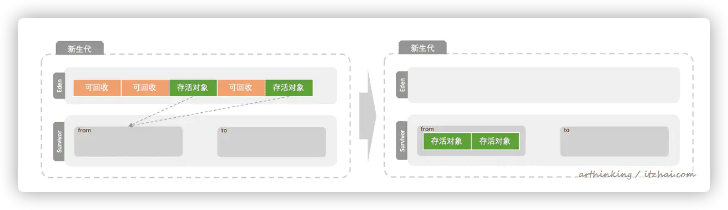
再次触发Young GC,扫描Eden区和from区,把存活的对象复制到To区,清空Eden区和from区。如果此时Survivor区的空间不够了,就会提前把对象放入老年代。
默认的,这样来回交换15次后,如果对象最终还是存活,就放入老年代。
交换次数可以通过JVM参数MaxTenuringThreshold进行设置。
4.2.5、JVM内存模型
JDK8之前

JDK8

如上图,JDK8的方法区实现变成了元空间,元空间在本地内存中。
4.3、标记-整理算法
4.3.1、算法描述
标记过程与标记-清楚算法一样;
标记完成后,将存活对象向一端移动,然后直接清理掉边界以外的内存。

4.3.2、优点
不会产生内存碎片;
不需要浪费额外的空间进行分配担保;
4.3.3、不足
整理阶段存在效率问题,适合老年代这种垃圾回收频率不是很高的场景;
4.4、分代收集算法
当前商业虚拟机都采用该算法。
新生代:复制算法(CG后只有少量的对象存活)
老年代:标记-整理算法 或者 标记-清理算法(GC后对象存活率高)
5、垃圾回收器
这一步就是我们真正进行垃圾回收的过程了。
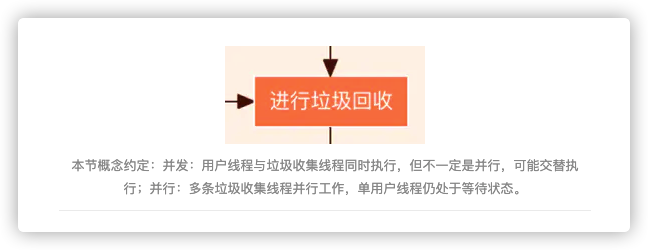
本节概念约定:并发:用户线程与垃圾收集线程同时执行,但不一定是并行,可能交替执行;并行:多条垃圾收集线程并行工作,单用户线程仍处于等待状态。
以下是垃圾收集器概览图
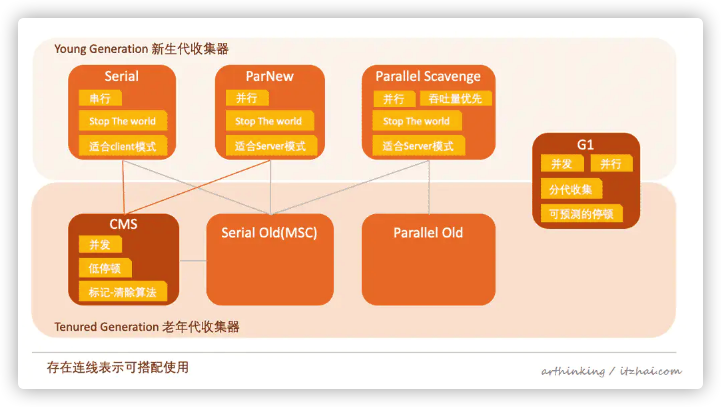
5.1、Serial收集器
5.1.1、特点
串行化:在垃圾回收时,必须赞同其他所有工作线程,知道收集结束,Stop The World;
在单CPU模式下无线程交互开销,专心做垃圾收集,简单高效。
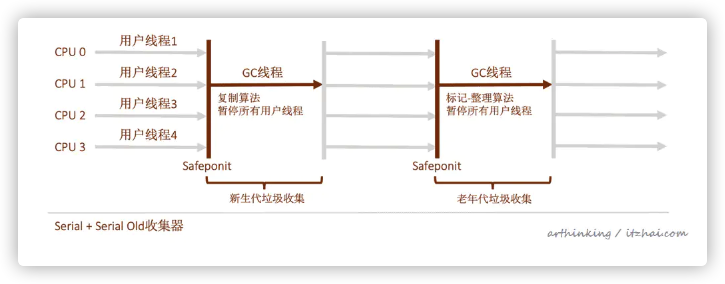
5.1.2、适用场景
特别适合限定单CPU的环境;
Client模式下的默认新生代收集器,用户桌面应用场景分配给虚拟机的内存一般不会很大,所以停顿时间也是在一百多毫秒以内,影响不大。
5.2、ParNew收集器
Parallel New?
5.2.1、特点
Serial收集器的多线程版本;
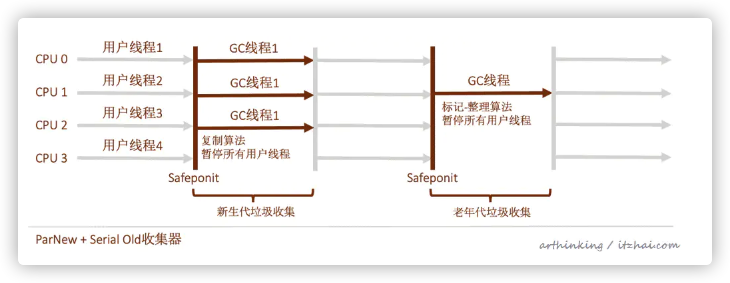
5.2.2、适用场景
许多运行在Server模式下的虚拟机中的首选新生代收集器;
除了Serial收集器外,只有它能和CMS收集器搭配使用。
-XX:+UseConcMarkSweepGC选型默认使用ParNew收集器。也可以使用-XX:+UseParNewGC选项强制指定它。
ParNew收集器在单CPU环境比Serial收集器效果差(存在线程交互开销)。
CPU数量越多,ParNew效果越好,默认开启收集线程数=CPU数量。可以使用-XX:ParallelGCThreads参数限制垃圾收集器的线程数。
5.3、Parallel Scavenge收集器
5.3.1、特点
新生代收集器,使用复制算法,并行多线程;
吞吐量优先收集器:CMS等收集器会关注如何缩短停顿时间,而这个收集器是为了吞吐量而设计的。
吞吐量 = 运行用户代码时间 / ( 运行用户代码时间 + 垃圾收集时间 )
也就是说整体垃圾收集时间越短,吞吐量越高。
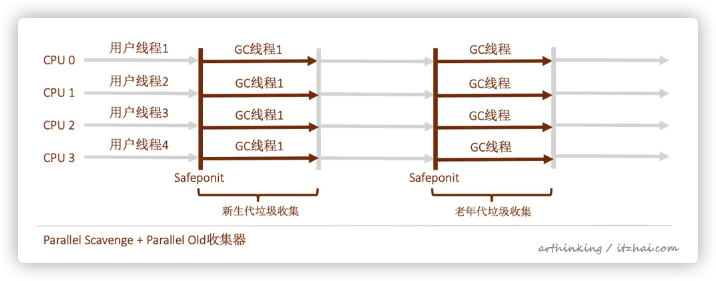
5.3.2、适用场景
可以高效利用CPU时间,尽快完成程序的运算任务,适合后台运算不需要太多交互的任务;
5.3.3、相关参数
-XXMaxGCPauseMillis:设置最大垃圾收集停顿时间,大于0的毫秒数;
缩短GC停顿时间会牺牲吞吐量和新生代空间。新生代空间小,GC回收就快,但是同时会导致GC更加频繁,整体垃圾回收时间更长。
-XX:GCTimeRatio:设置吞吞量大小。0~100的整数,垃圾收集时间占总时间的比率,相当于吞吐量的倒数。
19: 1/(1+19)= 5%,即最大GC时间占比5%;
99: 1/(1+99)=1%,即最大GC时间占比1%;
-XX:+UseAdaptiveSizePolicy:GC自适应调节策略开关,打开开关,无需手工指定-Xmn(新生代大小)、-XX:SurvivorRatio(Eden与Survivor区比例)、-XX:PretenureSizeThreshold(晋升老年代对象年龄)等参数,虚拟机会收集性能监控信息,动态调整这些参数,确保提供最合适的 停顿时间或者最大吞吐量。
5.4、Serial Old收集器
5.4.1、特点
Serial收集器的老年代版本。使用单线程,标记-整理算法。
5.4.2、适用场景
主要给Client模式下的虚拟机使用;
Server模式下,量大用途:
JDK1.5版本之前的版本与Parallel Scavenge收集器搭配使用;
作为CMS收集器的后备预案,发生Concurrent Mode Failure时使用。
5.5、Parallel Olde收集器
5.5.1、特点
Parallel Scavenge收集器的老年代版本,使用多线程,标记整理算法。
5.5.2、使用场景
主要配合Parallel Scavenge使用,提高吞吐量。在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑这个组合。
JDK1.6之后提供,之前Parallel Scavenge只能与Serial Old配合使用,老年代Serial Old无法充分利用服务器多CPU处理器能力,拖累了实际的吞吐量,效果不如ParNew+CMS组合;
5.6、CMS收集器
Concurrent Mark Sweep
5.6.1、特点
设计目标:获得最短回收停顿时间;
注重服务响应速度;
标记-清除算法;
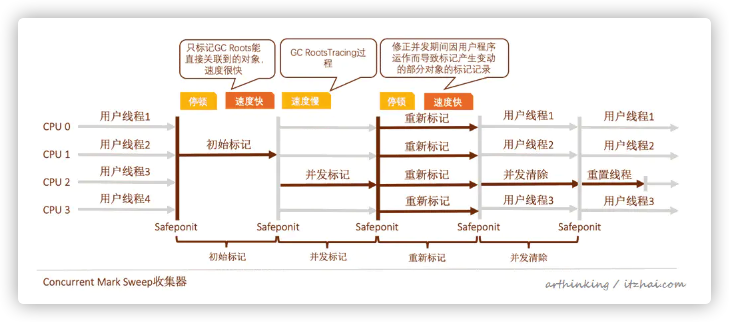
5.6.2、缺点
对CPU资源敏感,虽然不会导致用户线程停顿,但是会占用一部分线程(CPU资源)而导致应用程序变慢,吞吐量降低;
CMS收集器无法处理浮动垃圾。在CMS并发清理阶段,用户线程会产生垃圾。如果出现Concurrent Mode Failure失败,会启动后备预案:临时启动Serial Old收集器重新进行老年代垃圾收集,停顿时间更长了。-XX:CM SInitiatingOccupancyFraction设置的太高容易导致这个问题;
基于标记-清除算法,会产生大量空间碎片。
5.6.3、使用场景
互联网网站或者B/S系统的服务器;
5.6.4、相关参数
-XX:+UseCMSCompactAtFullCollection:在CMS要进行Full GC时进行内存碎片整理(默认开启)。内存整理过程无法并发,会增加停顿时间;
-XX:CMSFullGCsBeforeCompaction:在多少次 Full GC 后进行一次空间整理(默认0,即每一次 Full GC 后都进行一次空间整理);
-XX:CM SInitiatingOccupancyFraction:触发GC的内存百分比,设置的太高容易导致Concurrent Mode Failure失败(GC过程中,用户线程新增的浮动垃圾,导致触发另一个Full GC)。
CMS为什么要采用标记-清除算法?
CMS主要关注低延迟,所以采用并发方式清理垃圾,此时程序还在运行,如果采用压缩算法,则会涉及到移动应用程序的存活对象,这种场景下不做停顿是很难处理的,一般需要停顿下来移动存活对象,再让应用程序继续运行,但是这样停顿时间就边长了,延迟变长。CMS是容忍了空间碎片来换取回收的低延迟。
5.7、G1收集器
G1:Garbage-First,即优先回收价值最大的Region(注1)。
注1:G1与收集器将整个Java堆换分为多个代销相等的独立区域,跟踪各个Region里面的垃圾堆积的价值大小,优先回收价值最大的Region。
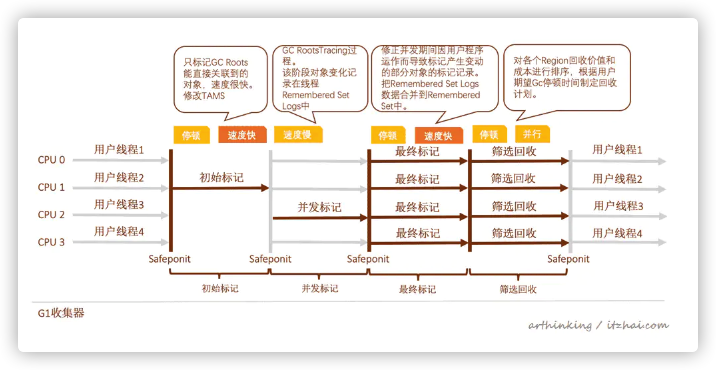
如上图,G1收集器分为四个阶段:
初始标记:只标记GC Roots能直接关联到的对象,速度很快。并修改TAMS(Next Top at Mark Start)的值,让下一阶段用户程序并发运行时,能够在正确可用的Region中创建新对象,这阶段需要停顿线程;
并发标记:GC RootsTracing过程。该阶段对象变化记录在线程Remembered Set Logs中。
最终标记:修正并发期间因用户程序运作而导致标记产生变动的部分对象的标记记录。把Remembered Set Logs数据合并到Remembered Set中。这个阶段需要停顿,但是可并行执行;
筛选回收:对各个Region回收价值和成本进行排序,根据用户期望Gc停顿时间制定回收计划。与CMS不一样,这里不用和用户线程并发执行,提高收集效率,使用标记-整理算法,不产生空间碎片。
5.7.1、特点
并行与并发:并发标记,并行最终标记与筛选回收;
分代收集
空间整合:基于标记-整理算法,不会产生碎片。
可预测的停顿:G与收集器将整个Java堆换分为多个代销相等的独立区域,避免在整个Java堆中进行全区域的垃圾回收,跟踪各个Region里面垃圾堆积的价值大小,后台维护一个优先列表,每次根据运行的收集时间,优先回收价值最大的Region。
四、什么是类加载?何时类加载?类加载流程?
类的加载过程介绍
介绍
类的加载指的是将类的 .class 文件中的二进制数据读入到 JVM 内存中,将其放在运行时数据区的 方法区 内,然后在 堆区 创建一个 java.lang.Class 对象,用来封装类在方法区内的数据结构。类的加载的最终是位于堆区中的 Class 对象,Class 对象封装了类在方法区内的数据结构,并且提供了访问方法区内的数据结构的接口。
类的加载过程分为 3 个步骤:加载;连接(验证、准备、解析);初始化,一般情况下 JVM 会连续完成 3 个步骤,有时也会只完成前两步。
如图

类加载过程.jpg
类加载器介绍
- 类加载介绍
- 系统可能在第一次使用某一个类时,加载该类,但也可能采用 预先加载机制 来加载该类,不管怎样类的加载必须由 类加载器 来完成。通常类加载器是由 JVM 提供。
- 类的加载必须由类加载器完成,通常情况下类加载器由 JVM 提供,但也可以通过自定义。
- JVM 提供的类加载器被称之为 系统类加载器
- 开发者还可以通过继承 ClassLoader 接口来创建 自定义类加载器
- 通过不同的类加载器,可以从不同的 “来源” 加载类的 .class 文件(二进制文件)
- 从本地系统中直接读取 .class 文件,大部分的加载方式。
- 从 ZIP、JAR 等归档文件中加载 .class 文件,很常见。
- 从网络下载 .class 文件数据。
- 从专有数据库中读取 .class 文件
- 将 Java 的源文件数据,上传到服务器中,进行动态编译产生 .class 文件,并加以执行。
- 但是不管 .class 文件数据来源何处,加载的结果都是相同的
- 将字节码文件数据加载到 JVM 内存中,将其放在运行时数据区的 方法区 内,然后在 堆区 创建一个 java.lang.Class 对象,用来封装类在方法区内的数据结构。类的加载的最终是位于堆区中的 Class 对象,Class 对象封装了类在方法区内的数据结构,并且提供了访问方法区内的数据结构的接口。
加载
作用
- 通过一个类的全限定名来获取其定义的字节码(二进制字节流),将字节码文件加载到 JVM 内存中,此过程由类加载器完成(可控)
特点
- 加载阶段是可控性最强的阶段,既可以使用系统提供的类加载器来完成加载,也可以自定义自己的类加载器来完成加载。
连接
验证
- 校验 .class 文件是否合法,遵循 .class 文件格式 参考地址
准备
- 为类变量(
static修饰的变量)在 JVM 方法区中分配内存,并进行 默认初始化int默认初始化为0- 引用默认初始化为
null - 等等
- 静态常量(
static final) ,有所不同,直接在 JVM 方法去中 显示初始化
- 为类变量(
解析
- JVM 将常量池的符号引用。替换为直接(地址)引用
特点
- 此时在堆区中已经创建一个 java.lang.Class 对象,指向方法区中的数据
初始化
作用
- 主要是对类静态的类变量进行 显示初始化 参考地址
- init 对非静态变量解析初始化
- clinit 是 java.lang.class 类构造器对静态变量,静态代码块进行初始化
- 类构造器方法(clinit)由编译器收集类中所有类变量的 显示赋值和静态代码块中的语句合并产生
- 主要是对类静态的类变量进行 显示初始化 参考地址
特点
- 当初始化某个类时,如果其父类没有初始化,则先触发父类的初始化动作
- JVM 保证一个类的初始化,在多线中中正确加锁和同步
何时会或者不会触发类初始化动作呢?
介绍
- 上面已经介绍,类的加载过程分为 3 步,大部分 3 步按顺序完成,有时也会只完成前两步
如何区分会不会触发类的初始化
- 如表
会触发类的初始化 不会触发类的初始化 当虚拟机启动时,先初始化 main()方法所在的类引用静态常量不会触发此类的初始化 一次 new一个类的对象(在 JVM 中一个类的 Class 对象只有一个)当访问一个静态域时,只有真正声明该域的类才会被初始化(子类继承父类的静态变量,在子类使用该静态变量时,只有父类会初始化,子类不会初始化) 调用该类的静态变量( static final除外,因为其在连接时已经显示初始化完成)和静态方法通过数组定义类引用时,不会触发类初始化( A[] as = new A[2]A 是类,此时不会初始化 A类)当初始化某个类时,其父类没有被初始化时,则会先初始化其父类
- 如表
五、知道哪些类加载器。类加载器之间的关系?
一、三种类加载器
当 JVM 启动的时候,Java 缺省开始使用如下三种类型的类加载器:
启动(Bootstrap)类加载器:引导类加载器是用 本地代码实现的类加载器,它负责将 <JAVA_HOME>/lib 下面的核心类库 或 -Xbootclasspath 选项指定的 jar 包等 虚拟机识别的类库 加载到内存中。由于引导类加载器涉及到虚拟机本地实现细节,开发者无法直接获取到启动类加载器的引用,所以 不允许直接通过引用进行操作。
扩展(Extension)类加载器:扩展类加载器是由 Sun 的 ExtClassLoader(sun.misc.Launcher$ExtClassLoader)实现的,它负责将 <JAVA_HOME>/lib/ext 或者由系统变量 - Djava.ext.dir 指定位置中的类库 加载到内存中。开发者可以直接使用标准扩展类加载器。
系统(System)类加载器:系统类加载器是由 Sun 的 AppClassLoader(sun.misc.Launcher$AppClassLoader)实现的,它负责将 用户类路径 (java -classpath 或 - Djava.class.path 变量所指的目录,即当前类所在路径及其引用的第三方类库的路径。开发者可以直接使用系统类加载器。
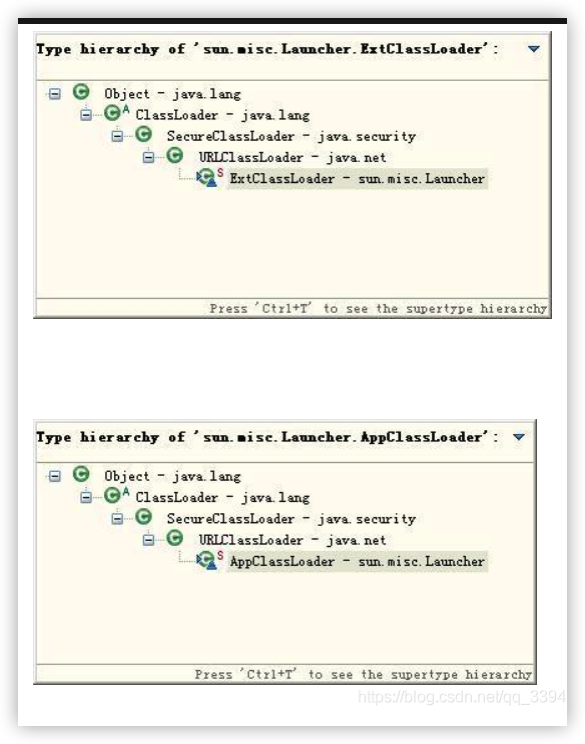
通过这两张图我们可以看出,扩展类加载器和系统类加载器均是继承自 java.lang.ClassLoader 抽象类。
二、类加载器的关系
关系如下:
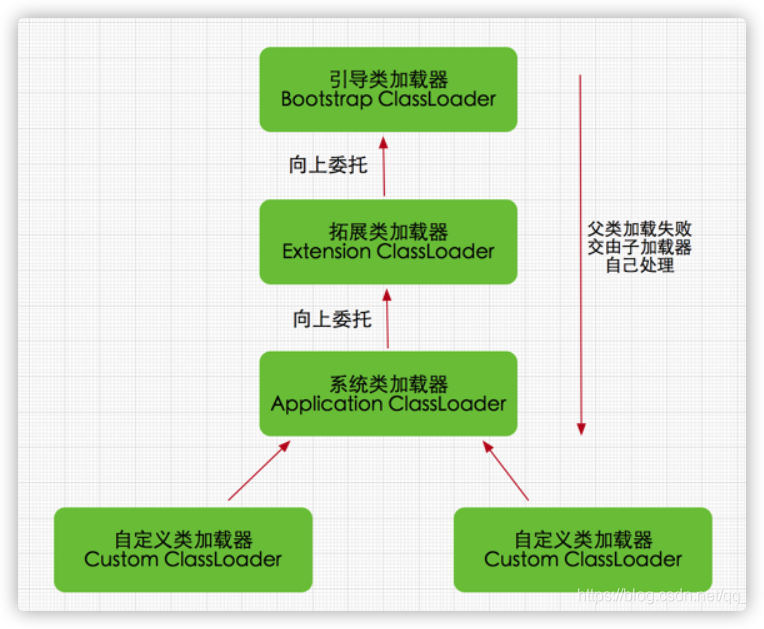
上面图片给人的直观印象是:系统类加载器的父类加载器是标准扩展类加载器,标准扩展类加载器的父类加载器是启动类加载器。
事实上,由于启动类加载器无法被 Java 程序直接引用,因此 JVM 默认直接使用 null 代表启动类加载器。
此外:
1.系统类加载器(AppClassLoader)调用 ClassLoader (ClassLoader parent) 构造函数将父类加载器设置为标准扩展类加载器 (ExtClassLoader)。(因为如果不强制设置,默认会通过调用 getSystemClassLoader () 方法获取并设置成系统类加载器。)
2.扩展类加载器(ExtClassLoader)调用 ClassLoader (ClassLoader parent) 构造函数将父类加载器设置为 null(null 本身就代表着引导类加载器)。(因为如果不强制设置,默认会通过调用 getSystemClassLoader () 方法获取并设置成系统类加载器,。)
六、类加载器的双亲委派了解么? 结合 Tomcat 说一下双亲委派(Tomcat 如何打破双亲委托机制?…)。
这是我们研究Tomcat的第四篇文章,前三篇文章我们搭建了源码框架,了解了tomcat的大致的设计架构, 还写了一个简单的服务器。按照我们最初订的计划,今天,我们要开始研究tomcat的几个主要组件(组件太多,无法一一解析,解析几个核心),包括核心的类加载器,连接器和容器,还有生命周期,还有pipeline 和 valve。一个一个来,今天来研究类加载器。
我们分为4个部分来探讨:
1. 什么是类加载机制?
2. 什么是双亲委任模型?
3. 如何破坏双亲委任模型?
4. Tomcat 的类加载器是怎么设计的?
我想,在研究tomcat 类加载之前,我们复习一下或者说巩固一下java 默认的类加载器。楼主以前对类加载也是懵懵懂懂,借此机会,也好好复习一下。
楼主翻开了神书《深入理解Java虚拟机》第二版,p227, 关于类加载器的部分。请看:
1. 什么是类加载机制?
代码编译的结果从本地机器码转变成字节码,是存储格式的一小步,却是编程语言发展的一大步。
Java虚拟机把描述类的数据从Class文件加载进内存,并对数据进行校验,转换解析和初始化,最终形成可以呗虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这动作的代码模块成为“类加载器”。
类与类加载器的关系
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载他的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类命名空间。这句话可以表达的更通俗一些:比较两个类是否“相等”,
只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来自同一个Class文件,被同一个虚拟机加载,只要加载他们的类加载器不同,那这个两个类就必定不相等。
2. 什么是双亲委任模型
- 从Java虚拟机的角度来说,只存在两种不同类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现(只限HotSpot),是虚拟机自身的一部分;另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,并且全都继承自抽象类
java.lang.ClassLoader. - 从Java开发人员的角度来看,类加载还可以划分的更细致一些,绝大部分Java程序员都会使用以下3种系统提供的类加载器:
- 启动类加载器(Bootstrap ClassLoader):这个类加载器复杂将存放在 JAVA_HOME/lib 目录中的,或者被-Xbootclasspath 参数所指定的路径种的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录下也不会重载)。
- 扩展类加载器(Extension ClassLoader):这个类加载器由sun.misc.Launcher$ExtClassLoader实现,它负责夹杂JAVA_HOME/lib/ext 目录下的,或者被java.ext.dirs 系统变量所指定的路径种的所有类库。开发者可以直接使用扩展类加载器。
- 应用程序类加载器(Application ClassLoader):这个类加载器由sun.misc.Launcher$AppClassLoader 实现。由于这个类加载器是ClassLoader 种的getSystemClassLoader方法的返回值,所以也成为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库。开发者可以直接使用这个类加载器,如果应用中没有定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
这些类加载器之间的关系一般如下图所示:
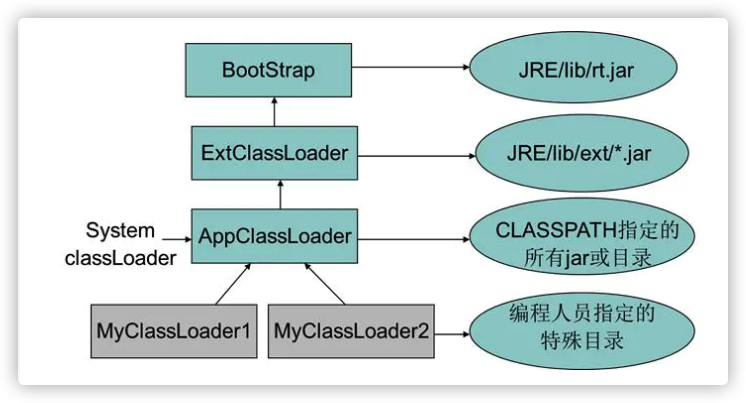
图中各个类加载器之间的关系成为 类加载器的双亲委派模型(Parents Dlegation Mode)。双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载,这里类加载器之间的父子关系一般不会以继承的关系来实现,而是都使用组合关系来复用父加载器的代码。
类加载器的双亲委派模型在JDK1.2 期间被引入并被广泛应用于之后的所有Java程序中,但他并不是个强制性的约束模型,而是Java设计者推荐给开发者的一种类加载器实现方式。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,他首先不会自己去尝试加载这个类,而是把这个请求委派父类加载器去完成。每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个请求(他的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
为什么要这么做呢?
如果没有使用双亲委派模型,由各个类加载器自行加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统将会出现多个不同的Object类, Java类型体系中最基础的行为就无法保证。应用程序也将会变得一片混乱。
双亲委任模型时如何实现的?
非常简单:所有的代码都在java.lang.ClassLoader中的loadClass方法之中,代码如下:
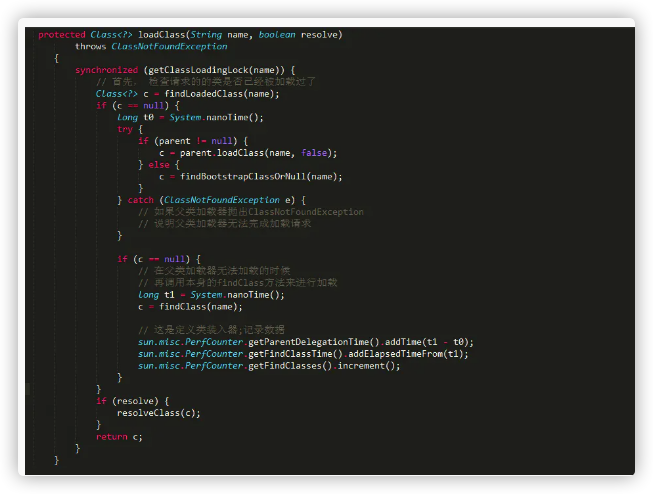
逻辑清晰易懂:先检查是否已经被加载过,若没有加载则调用父加载器的loadClass方法, 如父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException 异常后,再调用自己的findClass方法进行加载。
3. 如何破坏双亲委任模型?
刚刚我们说过,双亲委任模型不是一个强制性的约束模型,而是一个建议型的类加载器实现方式。在Java的世界中大部分的类加载器都遵循者模型,但也有例外,到目前为止,双亲委派模型有过3次大规模的“被破坏”的情况。 第一次:在双亲委派模型出现之前—–即JDK1.2发布之前。 第二次:是这个模型自身的缺陷导致的。我们说,双亲委派模型很好的解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API, 但没有绝对,如果基础类调用会用户的代码怎么办呢?
这不是没有可能的。一个典型的例子就是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK1.3时就放进去的rt.jar),但它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI, Service Provider Interface)的代码,但启动类加载器不可能“认识“这些代码啊。因为这些类不在rt.jar中,但是启动类加载器又需要加载。怎么办呢?
为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoader方法进行设置。如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过多的话,那这个类加载器默认即使应用程序类加载器。
嘿嘿,有了线程上下文加载器,JNDI服务使用这个线程上下文加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则。但这无可奈何,Java中所有涉及SPI的加载动作基本胜都采用这种方式。例如JNDI,JDBC,JCE,JAXB,JBI等。
第三次:为了实现热插拔,热部署,模块化,意思是添加一个功能或减去一个功能不用重启,只需要把这模块连同类加载器一起换掉就实现了代码的热替换。
书中还说到:
Java 程序中基本有一个共识:OSGI对类加载器的使用时值得学习的,弄懂了OSGI的实现,就可以算是掌握了类加载器的精髓。
牛逼啊!!!
现在,我们已经基本明白了Java默认的类加载的作用了原理,也知道双亲委派模型。说了这么多,差点把我们的tomcat给忘了,我们的题目是Tomcat 加载器为何违背双亲委派模型?下面就好好说说我们的tomcat的类加载器。
4. Tomcat 的类加载器是怎么设计的?
首先,我们来问个问题:
Tomcat 如果使用默认的类加载机制行不行?
我们思考一下:Tomcat是个web容器, 那么它要解决什么问题:
- 一个web容器可能需要部署两个应用程序,不同的应用程序可能会依赖同一个第三方类库的不同版本,不能要求同一个类库在同一个服务器只有一份,因此要保证每个应用程序的类库都是独立的,保证相互隔离。
- 部署在同一个web容器中相同的类库相同的版本可以共享。否则,如果服务器有10个应用程序,那么要有10份相同的类库加载进虚拟机,这是扯淡的。
- web容器也有自己依赖的类库,不能于应用程序的类库混淆。基于安全考虑,应该让容器的类库和程序的类库隔离开来。
- web容器要支持jsp的修改,我们知道,jsp 文件最终也是要编译成class文件才能在虚拟机中运行,但程序运行后修改jsp已经是司空见惯的事情,否则要你何用? 所以,web容器需要支持 jsp 修改后不用重启。
再看看我们的问题:Tomcat 如果使用默认的类加载机制行不行? 答案是不行的。为什么?我们看,第一个问题,如果使用默认的类加载器机制,那么是无法加载两个相同类库的不同版本的,默认的累加器是不管你是什么版本的,只在乎你的全限定类名,并且只有一份。第二个问题,默认的类加载器是能够实现的,因为他的职责就是保证唯一性。第三个问题和第一个问题一样。我们再看第四个问题,我们想我们要怎么实现jsp文件的热修改(楼主起的名字),jsp 文件其实也就是class文件,那么如果修改了,但类名还是一样,类加载器会直接取方法区中已经存在的,修改后的jsp是不会重新加载的。那么怎么办呢?我们可以直接卸载掉这jsp文件的类加载器,所以你应该想到了,每个jsp文件对应一个唯一的类加载器,当一个jsp文件修改了,就直接卸载这个jsp类加载器。重新创建类加载器,重新加载jsp文件。
Tomcat 如何实现自己独特的类加载机制?
所以,Tomcat 是怎么实现的呢?牛逼的Tomcat团队已经设计好了。我们看看他们的设计图:
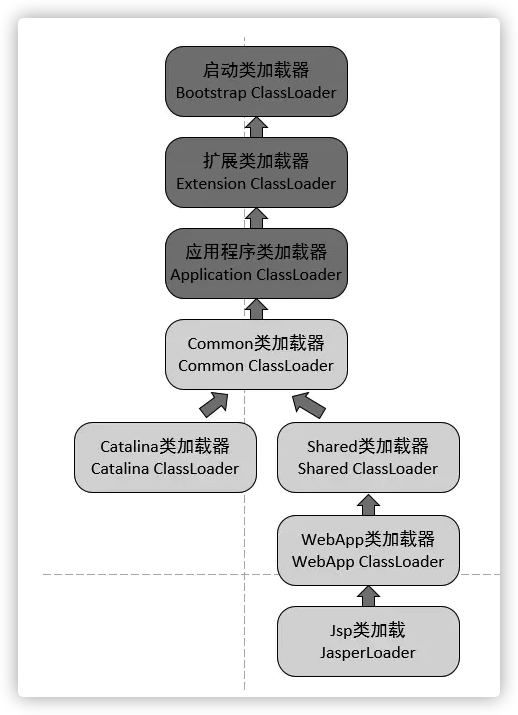
我们看到,前面3个类加载和默认的一致,CommonClassLoader、CatalinaClassLoader、SharedClassLoader和WebappClassLoader则是Tomcat自己定义的类加载器,它们分别加载/common/*、/server/*、/shared/*(在tomcat 6之后已经合并到根目录下的lib目录下)和/WebApp/WEB-INF/*中的Java类库。其中WebApp类加载器和Jsp类加载器通常会存在多个实例,每一个Web应用程序对应一个WebApp类加载器,每一个JSP文件对应一个Jsp类加载器。
- commonLoader:Tomcat最基本的类加载器,加载路径中的class可以被Tomcat容器本身以及各个Webapp访问;
- catalinaLoader:Tomcat容器私有的类加载器,加载路径中的class对于Webapp不可见;
- sharedLoader:各个Webapp共享的类加载器,加载路径中的class对于所有Webapp可见,但是对于Tomcat容器不可见;
- WebappClassLoader:各个Webapp私有的类加载器,加载路径中的class只对当前Webapp可见;
从图中的委派关系中可以看出:
CommonClassLoader能加载的类都可以被Catalina ClassLoader和SharedClassLoader使用,从而实现了公有类库的共用,而CatalinaClassLoader和Shared ClassLoader自己能加载的类则与对方相互隔离。
WebAppClassLoader可以使用SharedClassLoader加载到的类,但各个WebAppClassLoader实例之间相互隔离。
而JasperLoader的加载范围仅仅是这个JSP文件所编译出来的那一个.Class文件,它出现的目的就是为了被丢弃:当Web容器检测到JSP文件被修改时,会替换掉目前的JasperLoader的实例,并通过再建立一个新的Jsp类加载器来实现JSP文件的HotSwap功能。
好了,至此,我们已经知道了tomcat为什么要这么设计,以及是如何设计的,那么,tomcat 违背了java 推荐的双亲委派模型了吗?答案是:违背了。 我们前面说过:
双亲委派模型要求除了顶层的启动类加载器之外,其余的类加载器都应当由自己的父类加载器加载。
很显然,tomcat 不是这样实现,tomcat 为了实现隔离性,没有遵守这个约定,每个webappClassLoader加载自己的目录下的class文件,不会传递给父类加载器。
我们扩展出一个问题:如果tomcat 的 Common ClassLoader 想加载 WebApp ClassLoader 中的类,该怎么办?
看了前面的关于破坏双亲委派模型的内容,我们心里有数了,我们可以使用线程上下文类加载器实现,使用线程上下文加载器,可以让父类加载器请求子类加载器去完成类加载的动作。牛逼吧。
总结
好了,终于,我们明白了Tomcat 为何违背双亲委派模型,也知道了tomcat的类加载器是如何设计的。顺便复习了一下 Java 默认的类加载器机制,也知道了如何破坏Java的类加载机制。这一次收获不小哦!!! 嘿嘿。
七、常见调优参数有哪些?
-Xms2g:初始化推大小为 2g;
-Xmx2g:堆最大内存为 2g;
-XX:NewRatio=4:设置年轻的和老年代的内存比例为 1:4;
-XX:SurvivorRatio=8:设置新生代 Eden 和 Survivor 比例为 8:2;
–XX:+UseParNewGC:指定使用 ParNew + Serial Old 垃圾回收器组合;
-XX:+UseParallelOldGC:指定使用 ParNew + ParNew Old 垃圾回收器组合;
-XX:+UseConcMarkSweepGC:指定使用 CMS + Serial Old 垃圾回收器组合;
-XX:+PrintGC:开启打印 gc 信息;
-XX:+PrintGCDetails:打印 gc 详细信息。
八、……
数据库
学习了 MySQL 之后,务必确保自己掌握下面这些知识点:
一、MySQL 常用命令 :
1、MySQL常用命令
create database name; 创建数据库
use databasename; 选择数据库
drop database name 直接删除数据库,不提醒
show tables; 显示表
describe tablename; 表的详细描述
select 中加上distinct去除重复字段
mysqladmin drop databasename 删除数据库前,有提示。
显示当前mysql版本和当前日期
select version(),current_date;
2、修改mysql中root的密码:
shell>mysql -u root -p
mysql> update user set password=password(”xueok654123″) where user=’root’;
mysql> flush privileges //刷新数据库
mysql>use dbname; 打开数据库:
mysql>show databases; 显示所有数据库
mysql>show tables; 显示数据库mysql中所有的表:先use mysql;然后
mysql>describe user; 显示表mysql数据库中user表的列信息);
3、grant
创建一个可以从任何地方连接服务器的一个完全的超级用户,但是必须使用一个口令something做这个
mysql> grant all privileges on *.* to user@localhost identified by ’something’ with
增加新用户
格式:grant select on 数据库.* to 用户名@登录主机 identified by “密码”
GRANT ALL PRIVILEGES ON *.* TO monty@localhost IDENTIFIED BY ’something’ WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO monty@”%” IDENTIFIED BY ’something’ WITH GRANT OPTION;
删除授权:
mysql> revoke all privileges on *.* from root@”%”;
mysql> delete from user where user=”root” and host=”%”;
mysql> flush privileges;
创建一个用户custom在特定客户端it363.com登录,可访问特定数据库fangchandb
mysql >grant select, insert, update, delete, create,drop on fangchandb.* to custom@ [it363.com](https://link.jianshu.com?t=http://it363.com) identified by ‘ passwd’
重命名表:
mysql > alter table t1 rename t2;
4、mysqldump
备份数据库
shell> mysqldump -h host -u root -p dbname >dbname_backup.sql
恢复数据库
shell> mysqladmin -h myhost -u root -p create dbname
shell> mysqldump -h host -u root -p dbname < dbname_backup.sql
如果只想卸出建表指令,则命令如下:
shell> mysqladmin -u root -p -d databasename > a.sql
如果只想卸出插入数据的sql命令,而不需要建表命令,则命令如下:
shell> mysqladmin -u root -p -t databasename > a.sql
那么如果我只想要数据,而不想要什么sql命令时,应该如何操作呢?
mysqldump -T./ phptest driver
其中,只有指定了-T参数才可以卸出纯文本文件,表示卸出数据的目录,./表示当前目录,即与mysqldump同一目录。如果不指定driver 表,则将卸出整个数据库的数据。每个表会生成两个文件,一个为.sql文件,包含建表执行。另一个为.txt文件,只包含数据,且没有sql指令。
5、可将查询存储在一个文件中并告诉mysql从文件中读取查询而不是等待键盘输入。可利用外壳程序键入重定向实用程序来完成这项工作。
例如,如果在文件my_file.sql 中存放有查
询,可如下执行这些查询:
例如,如果您想将建表语句提前写在sql.txt中:
mysql > mysql -h myhost -u root -p database < sql.txt
二、MySQL 中常用的数据类型、字符集编码
MySQL 支持多种数据类型,主要有数值类型、日期/时间类型和字符串类型。
- 数值类型:包括整数类型
TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT、浮点小数数据类型FLOAT和DOUBLE、定点小数类型DECIMAL。 - 日期/时间类型:
YEAR、TIME、DATE、DATETIME和TIMESTAMP。 - 字符串类型:
CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM、SET。
整数类型
MySQL中的整数型数据类型:
| 类型名称 | 存储需求 |
|---|---|
| TINYINT | 1个字节 |
| SMALLINT | 2个字节 |
| MEDIUMINT | 3个字节 |
| INT(INTEGER) | 4个字节 |
| BIGINT | 8个字节 |
日期与时间类型
| 类型名称 | 日期格式 | 日期范围 | 存储需求 |
|---|---|---|---|
| YEAR | YYYY | 1901~2155 | 1个字节 |
| TIME | HH:MM:SS | -838:59:59~838:59:59 | 3个字节 |
| DATE | YYYY-MM-DD | 1000-01-01~9999-12-3 | 3个字节 |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00~9999-12-31 23:59:59 | 8个字节 |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:01 UTC ~2038-01-19 03:14:07 UTC | 4个字节 |
在这里提一下** CURRENT_DATE 和 NOW() 的区别**:CURRENT_DATE 返回当前日期值,不包括时间部分,NOW() 函数返回日期和时间值。
提示:TIMESTAMP 和 DATATIME 除了存储字节和支持的范围不同外,还有一个最大的区别就是:DATETIME 在存储日期数据时,按实际输入的格式存储,即输入什么就存储什么,与时区无关;而 TIMESTAMP 值的存储是以 UTC (世界标准时间)格式保存的,存储时对当前时区进行转换,检索时再转换回当前时区。即查询时,根据当前时区的不同,显示的时间值是不同的。
字符串类型
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串 | M字节,1<=M<= 255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,L<=M和1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此L<2^32 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此L<2^32 |
| ENUM | 枚举类型,只能存一个枚举字符串值 | 1或2个字节,取决于枚举值的数目(最大值65535) |
| SET | 一个设置,字符串对象可以有零个或多个 SET 成员 | 1、2、3、4或8个字节,取决于集合成员的数量(最多64个成员) |
三、MySQL 简单查询、条件查询、模糊查询、多表查询以及如何对查询结果排序、过滤、分组……
四、MySQL 中使用索引、视图、存储过程、游标、触发器
1 索引 2 触发器 3 存储过程和函数 4 视图 5 基本的数据库建表语句练习
1 索引
(1)基本概念
https://blog.csdn.net/buhuikanjian/article/details/52966039
(2)建立索引的原则
https://www.cnblogs.com/aspwebchh/p/6652855.html
(3)具体操作语句
步骤1 创建表test_table1,添加三个索引
CREATE TABLE test_table1(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
NAME CHAR(100) NOT NULL,
address CHAR(100) NOT NULL,
description CHAR(100) NOT NULL,
UNIQUE INDEX UniqIdx(id),
INDEX MultiColIdx(NAME(20), address(30)),
INDEX ComIdx(description(30))
);
步骤2 创建表test_table1,添加三个索引创建表test_table2,存储引擎为MyISAM
CREATE TABLE test_table2(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
firstname CHAR(100) NOT NULL,
middlename CHAR(100) NOT NULL,
lastname CHAR(100) NOT NULL,
birth DATE NOT NULL,
title CHAR(100) NULL
) ENGINE=MYISAM;
步骤3 创建表test_table1,添加三个索引使用ALTER TABLE语句在表test_table2的birth字段上,建立名称为ComDateIdx的普通索引
ALTER TABLE test_table2 ADD INDEX ComDateIdx(birth);
步骤4 创建表test_table1,添加三个索引使用ALTER TABLE语句在表test_table2的id字段上,添加名称为UniqIdx2的唯一索引,并以降序排列
ALTER TABLE test_table2 ADD UNIQUE INDEX UniqIdx2 (id DESC);
步骤5 创建表test_table1,添加三个索引使用CREATE INDEX在firstname、middlename和lastname3个字段上建立名称为MultiColIdx2的组合索引
CREATE INDEX MultiColIdx2 ON test_table2(firstname, middlename, lastname);
步骤6 创建表test_table1,添加三个索引使用CREATE INDEX在title字段上建立名称为FTIdx的全文索引
CREATE FULLTEXT INDEX FTIdx ON test_table2(title);
步骤7 创建表test_table1,添加三个索引使用ALTER TABLE语句删除表test_table1中名称为UniqIdx的唯一索引
ALTER TABLE test_table1 DROP INDEX UniqIdx;
步骤8 创建表test_table1,添加三个索引使用DROP INDEX语句删除表test_table2中名称为MultiColIdx2的组合索引
DROP INDEX MultiColIdx2 ON test_table2;
2 触发器

(2)触发器使用
https://www.cnblogs.com/yank/p/4193820.html
3 存储过程和函数
(1)存储过程优缺点
https://blog.csdn.net/jackmacro/article/details/5688687
(2)存储过程、函数、游标
https://www.cnblogs.com/doudouxiaoye/p/5811836.html https://www.cnblogs.com/jacketlin/p/7874009.html
(3)代码详解
1 创建查看fruits表的存储过程,创建了一个查看fruits表的存储过程,每次调用这个存储过程的时候都会执行SELECT语句查看表的内容。
CREATE PROCEDURE Proc()
BEGIN
SELECT * FROM fruits;
END ;
2 创建名称为CountProc的存储过程,获取fruits表记录条数。COUNT(*) 计算后把结果放入参数param1中。 当使用DELIMITER命令时,应该避免使用反斜杠(’\’)字符,因为反斜线是MySQL的转义字符。
CREATE PROCEDURE CountProc (OUT param1 INT)
BEGIN
SELECT COUNT(*) INTO param1 FROM fruits;
END;
3 创建存储函数NameByZip,该函数返回SELECT语句的查询结果,数值类型为字符串型。
CREATE FUNCTION NameByZip ()
RETURNS CHAR(50)
RETURN (SELECT s_name FROM suppliers WHERE s_call= '48075');
4 定义名称为myparam的变量,类型为INT类型,默认值为100。
DECLARE myparam INT DEFAULT 100;
5 声明3个变量,分别为var1、var2和var3,数据类型为INT,使用SET为变量赋值。
DECLARE var1, var2, var3 INT;
SET var1 = 10, var2 = 20;
SET var3 = var1 + var2;
MySQL中还可以通过SELECT … INTO为一个或多个变量赋值,语法如下:
SELECT col_name[,...] INTO var_name[,...] table_expr;
这个SELECT语法把选定的列直接存储到对应位置的变量。col_name表示字段名称;var_name表示定义的变量名称;table_expr表示查询条件表达式,包括表名称和WHERE子句。
6 声明变量fruitname和fruitprice,通过SELECT,INTO语句查询指定记录并为变量赋值。
DECLARE fruitname CHAR(50);
DECLARE fruitprice DECIMAL(8,2);
SELECT f_name,f_price INTO fruitname, fruitprice
FROM fruits WHERE f_id ='a1';
7 声明名称为cursor_fruit的光标
DECLARE cursor_fruit CURSOR FOR SELECT f_name, f_price FROM fruits ;
8 使用名称为cursor_fruit的光标。将查询出来的数据存入fruit_name和fruit_price这两个变量中。
FETCH cursor_fruit INTO fruit_name, fruit_price ;
9 IF语句的示例
IF val IS NULL
THEN SELECT 'val is NULL';
ELSE SELECT 'val is not NULL';
END IF;
10 使用CASE流程控制语句的第1种格式,判断val值等于1、等于2,或者两者都不等。
CASE val
WHEN 1 THEN SELECT 'val is 1';
WHEN 2 THEN SELECT 'val is 2';
ELSE SELECT 'val is not 1 or 2';
END CASE;
11 使用LOOP语句进行循环操作,id值小于等于10之前,将重复执行循环过程。
DECLARE id INT DEFAULT 0;
add_loop: LOOP
SET id = id + 1;
IF id >= 10 THEN LEAVE add_loop;
END IF;
END LOOP add_ loop;
12 使用LEAVE语句退出循环。循环执行count加1的操作。当count的值等于50时,使用LEAVE语句跳出循环。
add_num: LOOP
SET @count=@count+1;
IF @count=50 THEN LEAVE add_num ;
END LOOP add_num ;
13 ITERATE语句示例。
CREATE PROCEDURE doiterate()
BEGIN
DECLARE p1 INT DEFAULT 0;
my_loop: LOOP
SET p1= p1 + 1;
IF p1 < 10 THEN ITERATE my_loop;
ELSEIF p1 > 20 THEN LEAVE my_loop;
END IF;
SELECT 'p1 is between 10 and 20';
END LOOP my_loop;
END
14 REPEAT语句示例,id值小于等于10之前,将重复执行循环过程。 该示例循环执行id加1的操作。当id值小于10时,循环重复执行;当id值大于或者等于10时,使用LEAVE语句退出循环。REPEAT循环都以END REPEAT结束。
DECLARE id INT DEFAULT 0;
REPEAT
SET id = id + 1;
UNTIL id >= 10
END REPEAT;
15 WHILE语句示例,id值小于等于10之前,将重复执行循环过程。
DECLARE i INT DEFAULT 0;
WHILE i < 10 DO
SET i = i + 1;
END WHILE;
16 定义名为CountProc1的存储过程,然后调用这个存储过程。
CREATE PROCEDURE CountProc1 (IN sid INT, OUT num INT)
BEGIN
SELECT COUNT(*) INTO num FROM fruits WHERE s_id = sid;
END //
4 视图
(1)视图的含义和作用
视图是数据库中的一个虚拟表。同真实的表一样,视图包含一系列的行和列数据。行和列数据来源于自由定义视图查询所引用的表,并且在引用视图是动态生成。
(2)视图和表的联系、区别

(3)视图基本操作
步骤1:创建学生表stu,插入3条记录。
CREATE TABLE stu
(
s_id INT PRIMARY KEY,
s_name VARCHAR(20),
addr VARCHAR(50),
tel VARCHAR(50)
);
INSERT INTO stu
VALUES(1,'XiaoWang','Henan','0371-12345678'),
(2,'XiaoLi','Hebei','13889072345'),
(3,'XiaoTian','Henan','0371-12345670');
步骤2:创建报名表sign,插入3条记录。
CREATE TABLE sign
(
s_id INT PRIMARY KEY,
s_name VARCHAR(20),
s_sch VARCHAR(50),
s_sign_sch VARCHAR(50)
);
INSERT INTO sign
VALUES(1,'XiaoWang','Middle School1','Peking University'),
(2,'XiaoLi','Middle School2','Tsinghua University'),
(3,'XiaoTian','Middle School3','Tsinghua University');
步骤3:创建成绩表stu_mark,插入3条记录。
CREATE TABLE stu_mark (s_id INT PRIMARY KEY ,s_name VARCHAR(20) ,mark int );
INSERT INTO stu_mark VALUES(1,'XiaoWang',80),(2,'XiaoLi',71),(3,'XiaoTian',70);
步骤4:创建考上Peking University的学生的视图
CREATE VIEW beida (id,name,mark,sch)
AS SELECT stu_mark.s_id,stu_mark.s_name,stu_mark.mark, sign.s_sign_sch
FROM stu_mark ,sign
WHERE stu_mark.s_id=sign.s_id AND stu_mark.mark>=41
AND sign.s_sign_sch='Peking University';
步骤5:创建考上qinghua University的学生的视图
CREATE VIEW qinghua (id,name,mark,sch)
AS SELECT stu_mark.s_id, stu_mark.s_name, stu_mark.mark, sign.s_sign_sch
FROM stu_mark ,sign
WHERE stu_mark.s_id=sign.s_id AND stu_mark.mark>=40
AND sign.s_sign_sch='Tsinghua University';
步骤6:XiaoTian的成绩在录入的时候录入错误多录了50分,对其录入成绩进行更正。
UPDATE stu_mark SET mark = mark-50 WHERE stu_mark.s_name ='XiaoTian';
步骤7:查看更新过后视图和表的情况。
SELECT * FROM stu_mark;
SELECT * FROM qinghua;
SELECT * FROM beida;
步骤8:查看视图的创建信息。
SELECT * FROM information_schema.views
步骤9:删除创建的视图。
DROP VIEW beida;
DROP VIEW qinghua;
5 基本的数据库建表语句练习(这个好像我真的是不会……)
建立一个数据库,逻辑名称为Student,包含1个数据文件和1个日志文件。数据文件初始大小为10M
if exists(select * from sys.sysdatabases where name='Student')
begin
use master
drop database Student
end
go
create database Student
on
--路径根据实际情况自行修改
(name=N'Student',filename=N'E:\Student.mdf',size=10mb,maxsize=unlimited,filegrowth=1)
log on
(name=N'Student',filename=N'E:\Student_log.ldf',size=10mb,maxsize=unlimited,filegrowth=1)
https://www.cnblogs.com/accumulater/p/6158294.html
创建表,增加约束。包括:主键约束、非空约束、性别范围约束、出生日期约束、年龄约束、外键约束、唯一性约束、评论约束、默认关键词约束
下面的语句可能不通顺,但是这些约束都有。check也可以使用enum代替。
CREATE TABLE tblstudent(
stuID BIGINT PRIMARY KEY NOT NULL,
stuName NVARCHAR(10) NOT NULL,
stuSex NCHAR(1) NOT NULL DEFAULT '男' CHECK (stuSex IN ('男','女')),
stuBirth DATETIME CHECK (stuBirth < getdate()) COMMENT '出生日期',
stuNum NVARCHAR(18) UNIQUE
Math INT CHECK(Sage > 18 AND Sage < 30) COMMENT '数学'
stuID BIGINT REFERENCES tblstudent(stuID)
)
https://www.cnblogs.com/ghost-xyx/p/3795679.html
drop,alter,insert,update,delete
https://blog.csdn.net/leftwukaixing/article/details/44415875
这个东西属于基础知识,可能不需要深入了解,但是不知道一定会有问题。
如果你想让自己更加了解 MySQL ,同时也是为了准备面试的话,下面这些知识点要格外注意:
一、索引:索引优缺点、B 树和 B+树、聚集索引与非聚集索引、覆盖索引
什么是索引?
索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
为什么要用索引?索引的优缺点分析
索引的优点
可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
索引的缺点
创建索引和维护索引需要耗费许多时间:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
占用物理存储空间 :索引需要使用物理文件存储,也会耗费一定空间。
B树和B+树区别
B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
Hash索引和 B+树索引优劣分析
Hash索引定位快
Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
Hash冲突问题
知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。
试想一种情况:
SELECT * FROM tb1 WHERE id < 500;
B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
索引类型
主键索引(Primary Key)
数据表的主键列使用的就是主键索引。
一张数据表有只能有一个主键,并且主键不能为null,不能重复。
在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。
二级索引(辅助索引)
二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。
唯一索引,普通索引,前缀索引等索引属于二级索引。
PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。
唯一索引(Unique Key) :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
普通索引(Index) :普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。
前缀索引(Prefix) :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,因为只取前几个字符。
全文索引(Full Text) :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
二级索引:
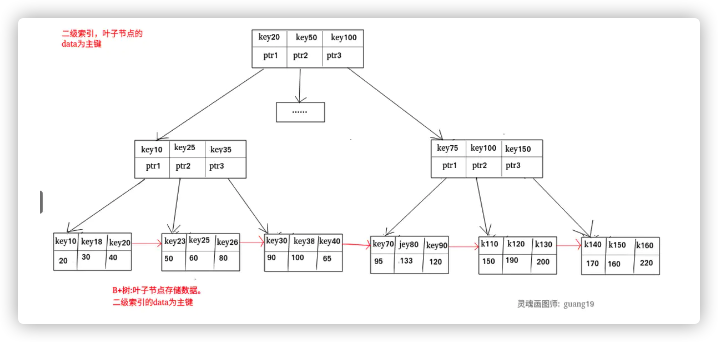
聚集索引与非聚集索引
聚集索引
聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。
在 Mysql 中,InnoDB引擎的表的 .ibd文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
聚集索引的优点
聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
聚集索引的缺点
依赖于有序的数据 :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
更新代价大 : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
非聚集索引
非聚集索引即索引结构和数据分开存放的索引。
二级索引属于非聚集索引。
MYISAM引擎的表的.MYI文件包含了表的索引,该表的索引(B+树)的每个叶子非叶子节点存储索引,叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
非聚集索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
非聚集索引的优点
更新代价比聚集索引要小 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
非聚集索引的缺点
跟聚集索引一样,非聚集索引也依赖于有序的数据
可能会二次查询(回表) :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
这是Mysql的表的文件截图:

聚集索引和非聚集索引:
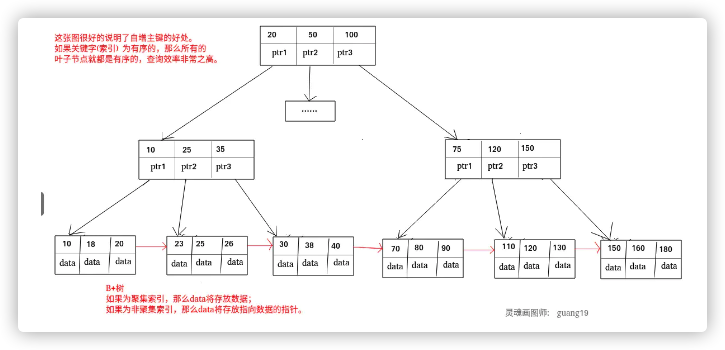
非聚集索引一定回表查询吗(覆盖索引)?
非聚集索引不一定回表查询。
试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
SELECT name FROM table WHERE username=‘guang19’;
那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?
SELECT id FROM table WHERE id=1;
主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。
如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
再如普通索引,如果一条SQL需要查询name,name字段正好有索引,那么直接根据这个索引就可以查到数据,也无需回表。
覆盖索引:
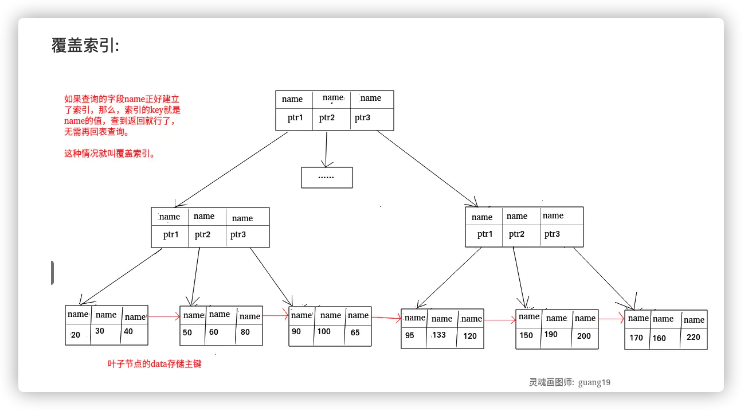
索引创建原则
- 单列索引
单列索引即由一列属性组成的索引。
联合索引(多列索引)
联合索引即由多列属性组成索引。
- 最左前缀原则
假设创建的联合索引由三个字段组成:
ALTER TABLE table ADD INDEX index_name (num,name,age)
那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
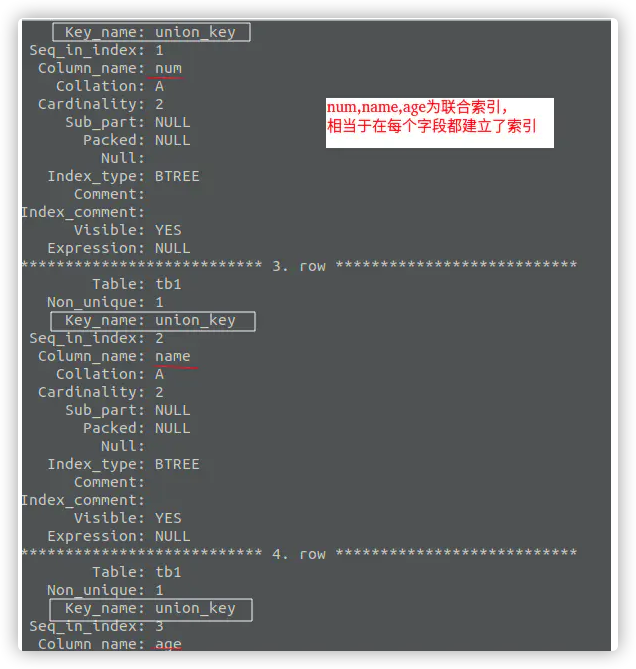
无论是否符合最左前缀原则,每个字段的索引都生效:
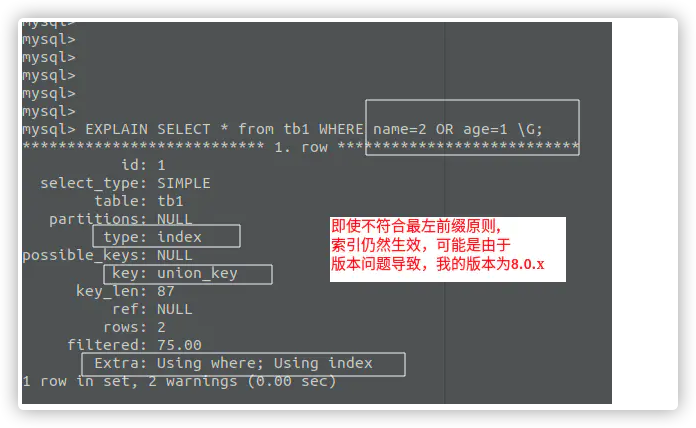
索引创建注意点
最左前缀原则
虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
选择合适的字段
1.不为NULL的字段
索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
2.被频繁查询的字段
我们创建索引的字段应该是查询操作非常频繁的字段。
3.被作为条件查询的字段
被作为WHERE条件查询的字段,应该被考虑建立索引。
4.被经常频繁用于连接的字段
经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
不合适创建索引的字段
1.被频繁更新的字段应该慎重建立索引
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
2.不被经常查询的字段没有必要建立索引
3.尽可能的考虑建立联合索引而不是单列索引
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
4.注意避免冗余索引
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
5.考虑在字符串类型的字段上使用前缀索引代替普通索引
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
使用索引一定能提高查询性能吗?
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
二、事务:事务、数据库事务、ACID、并发事务、事务隔离级别
事务具有四大特征,分别是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),简称为事务的ACID特性。
原子性(Atomicity)
原子性是指事务必须是一个原子的操作序列单元。事务中包含的各项操作在一次执行过程中,只允许出现以下两种状态之一。
- 全部成功执行
- 全部不执行
任何一项操作失败都将导致整个事务失败,同时其他已经被执行的操作都将被撤消并回滚,只有所有的操作全部成功,整个事务才算是成功完成。
一致性(Consistency)
一致性是指事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。也就是说事务的执行结果必须是使数据库从一个一致性状态转变到另一个一致性状态。因此当事务全部成功提交时,就能说数据库处于一致性状态,如果数据库运行过程中出现故障,导致有些事务尚未完成就被迫中断,这些未完成的事务中的部分操作已经写入的物理数据库,这时数据库就处于一种不一致的状态。
隔离性(Isolation)
隔离性是指在并发环境中,并发的事务是相互隔离的,一个事务的执行不能被其它事务干扰。也就是说,不同的事务并发操作相同的数据时,每个事务都有各自完整的数据空间,即一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰。
在标准的SQL规范中,定义了四个事务隔离级别,不同的隔离级别对事务的处理不同
- 未授权读取 也称读未提交(Read Uncommitted),该隔离级别允许脏读,隔离级别最低。
什么是脏读?
如果一个事务正在处理某一数据,对其进行了更新,但尚未提交事务,与此同时,另一个事务能够访问该事务更新后的数据。也就是说,事务的中间状态对其它事务是可见的。
举例说明: 用户A原工资为1000元 第一步:事务1执行修改操作,为用户A增加工资1000元,事务1尚未提交事务 第二步:事务2执行读取操作,查询到用户A的工资为2000元。
事务2读取到了事务1中尚未提交的修改结果,但是事务1尚未提交,有可能会因为后续操作失败而产生回滚。
- 授权读取 也称读已提交(Read Committed),该隔离级别禁止脏读,允许不可重复读。
什么是不可重复读?
一个事务过程中,对同一数据进行多次查询,查询的数据可能不一样,原因可能是两次查询过程中,另一个事务对该数据进行了修改并成功提交事务。也就是说,事务的结束状态对其它事务是可见的。
举例说明: 用户A原工资为1000元 第一步:事务1执行查询操作,查询到用户A的工资为1000元,事务1尚未提交事务。 第二步:事务2执行修改操作,为用户A的增加工资1000元。 第三步:事务1执行查询操作,查询到用户A的工资为2000元。
对于事务1来说,同一个事务里的多次查询,结果并不稳定。
- 可重复读取 可重复读取(Repeatable Read),该隔离级别禁止不可重复读和脏读,允许幻读。保证在事务处理过程中,多次读取同一数据,其值都和事务开始时刻是一致的。
什么是幻读?
不可重复读针对的是数据的修改,而幻读针对的是数据的新增。
举例说明:
用户表,用户名为唯一键
第一步:事务1执行查询操作,查询是否存在用户名为aaa的数据,事务1尚未提交
select 1 from user where username = 'aaa'
第二步:事务2执行插入操作,插入用户名为aaa的数据
第三步:事务1执行插入操作,插入用户为为aaa的数据,提示唯一键错误,插入失败。
对于事务一来说,查询用户aaa不存在,保存却报唯一键错误,如梦如幻,故名幻读。
- 串行化 串行化(Serializable)是最严格的事务隔离级别,它要求所有事务都被串行执行,即事务只能一个一个地进行处理,不能并发执行。
mysql 默认使用 Repeatable Read 级别,其它数据库大部分默认使用 Read Committed 级别
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未授权读取 | 存在 | 存在 | 存在 |
| 授权读取 | 不存在 | 存在 | 存在 |
| 可重复读取 | 不存在 | 不存在 | 存在 |
| 串行化 | 不存在 | 不存在 | 不存在 |
持久性(Durability)
持久性是指一个事务一旦提交,它对数据库中对应数据的状态变更就应该是永久性的。也就是说,它对数据库所做的更新就必须被永久保存一下,即使发生系统崩溃或机器宕机等故障,只要数据库能够重新启动,那么一定能够将其恢复到事务成功结束时的状态。
三、存储引擎(MyISAM 和 InnoDB)
1、MySQL默认存储引擎的变迁
在MySQL 5.1之前的版本中,默认的搜索引擎是MyISAM,从MySQL 5.5之后的版本中,默认的搜索引擎变更为InnoDB。
2、MyISAM与InnoDB存储引擎的主要特点
MyISAM存储引擎的特点是:表级锁、不支持事务和全文索引,适合一些CMS内容管理系统作为后台数据库使用,但是使用大并发、重负荷生产系统上,表锁结构的特性就显得力不从心;
以下是MySQL 5.7 MyISAM存储引擎的版本特性:
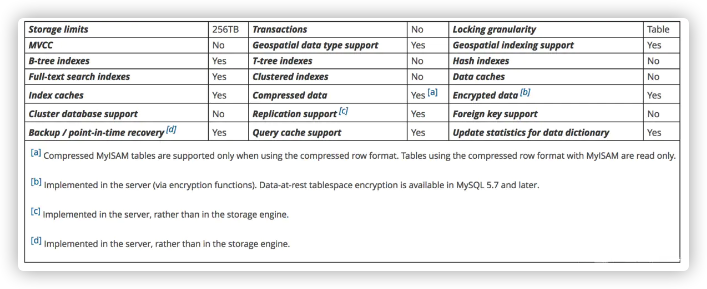
InnoDB存储引擎的特点是:行级锁、事务安全(ACID兼容)、支持外键、不支持FULLTEXT类型的索引(5.6.4以后版本开始支持FULLTEXT类型的索引)。InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全存储引擎。InnoDB是为处理巨大量时拥有最大性能而设计的。它的CPU效率可能是任何其他基于磁盘的关系数据库引擎所不能匹敌的。
以下是MySQL 5.7 InnoDB存储引擎的版本特性:
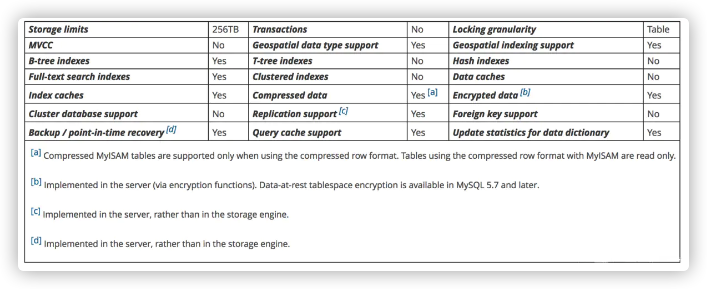
注意:
InnoDB表的行锁也不是绝对的,假如在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “a%”。
两种类型最主要的差别就是InnoDB支持事务处理与外键和行级锁。而MyISAM不支持。所以MyISAM往往就容易被人认为只适合在小项目中使用。
3、MyISAM与InnoDB性能测试
下边两张图是官方提供的MyISAM与InnoDB的压力测试结果
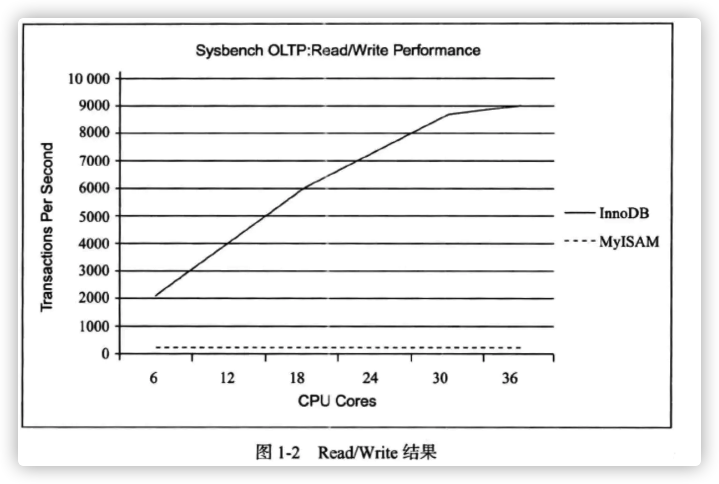
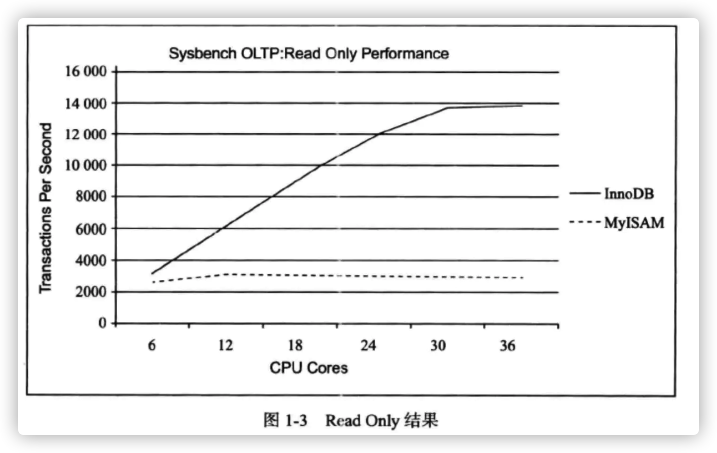
可以看出,随着CPU核数的增加,InnoDB的吞吐量反而越好,而MyISAM,其吞吐量几乎没有什么变化,显然,MyISAM的表锁定机制降低了读和写的吞吐量。
4、事务支持与否
MyISAM是一种非事务性的引擎,使得MyISAM引擎的MySQL可以提供高速存储和检索,以及全文搜索能力,适合数据仓库等查询频繁的应用;
InnoDB是事务安全的;
事务是一种高级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而MyISAM就不可以了。
5、MyISAM与InnoDB构成上的区别
(1)每个MyISAM在磁盘上存储成三个文件:
第一个文件的名字以表的名字开始,扩展名指出文件类型,.frm文件存储表定义。 第二个文件是数据文件,其扩展名为.MYD (MYData)。 第三个文件是索引文件,其扩展名是.MYI (MYIndex)。
(2)基于磁盘的资源是InnoDB表空间数据文件和它的日志文件,InnoDB 表的 大小只受限于操作系统文件的大小,一般为 2GB。
6、MyISAM与InnoDB表锁和行锁的解释
MySQL表级锁有两种模式:表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)。什么意思呢,就是说对MyISAM表进行读操作时,它不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写操作;而对MyISAM表的写操作,则会阻塞其他用户对同一表的读和写操作。
InnoDB行锁是通过给索引项加锁来实现的,即只有通过索引条件检索数据,InnoDB才使用行级锁,否则将使用表锁!行级锁在每次获取锁和释放锁的操作需要消耗比表锁更多的资源。在InnoDB两个事务发生死锁的时候,会计算出每个事务影响的行数,然后回滚行数少的那个事务。当锁定的场景中不涉及Innodb的时候,InnoDB是检测不到的。只能依靠锁定超时来解决。
7、是否保存数据库表中表的具体行数
InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。
注意的是,当count(*)语句包含where条件时,两种表的操作是一样的。也就是 上述“6”中介绍到的InnoDB使用表锁的一种情况。
8、如何选择
MyISAM适合:
- (1)做很多count 的计算;
- (2)插入不频繁,查询非常频繁,如果执行大量的SELECT,MyISAM是更好的选择;
- (3)没有事务。
InnoDB适合:
- (1)可靠性要求比较高,或者要求事务;
- (2)表更新和查询都相当的频繁,并且表锁定的机会比较大的情况指定数据引擎的创建;
- (3)如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表;
- (4)DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的 删除;
- (5)LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
要注意,创建每个表格的代码是相同的,除了最后的 TYPE参数,这一参数用来指定数据引擎。
其他区别:
1、对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。
2、DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
3、LOAD TABLE FROMMASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。
4、 InnoDB存储引擎被完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。
5、对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引。
6、清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表。
四、锁机制与 InnoDB 锁算法
1、 锁分类(按粒度分)
解决并发、数据安全的问题,用锁。
(1)表级锁
粒度最大,对整表加锁,实现简单 ,资源消耗也比较少,加锁快,不会出现死锁 。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
(2)行级锁
粒度最小。 减少数据库冲突。加锁粒度最小,并发度高,加锁开销最大,加锁慢,会出现死锁。 InnoDB支持的行级锁:
1)行锁 Record Lock: 对索引项加锁,锁定符合条件的行。其他事务不能修改和删除加锁项;
2)间隙锁 Gap Lock: 对索引项之间的“间隙”加锁,锁定记录的范围(对第一条记录前的间隙或最后一条将记录后的间隙加锁),不包含索引项本身。其他事务不能在锁范围内插入数据,这样就防止了别的事务新增幻影行。
3)行锁和间隙锁组合 Next-key Lock: 锁定索引项本身和索引范围。解决幻读问题。
虽行级索粒度小、并发度高等特点,但表级锁有时候非常必要:
事务更新大表中的大部分数据直接使用表级锁效率更高;用行级索很可能引起死锁导致回滚。
2、另外两个表级锁:IS和IX
当一个事务需要给自己需要的某个资源加锁的时候,如果遇到一个共享锁正锁定着自己需要的资源的时候,自己可以再加一个共享锁,不过不能加排他锁。但是,如果遇到自己需要锁定的资源已经被一个排他锁占有之后,则只能等待该锁定释放资源之后自己才能获取锁定资源并添加自己的锁定。而意向锁的作用就是当一个事务在需要获取资源锁定的时候,如果遇到自己需要的资源已经被排他锁占用的时候,该事务可以需要锁定行的表上面添加一个合适的意向锁。如果自己需要一个共享锁,那么就在表上面添加一个意向共享锁。而如果自己需要的是某行(或者某些行)上面添加一个排他锁的话,则先在表上面添加一个意向排他锁。意向共享锁可以同时并存多个,但是意向排他锁同时只能有一个存在。
InnoDB另外的两个表级锁:
意向共享锁(IS): 事务准备给数据行记入共享锁,事务在一个数据行加共享锁前必须先取得该表的IS锁。
意向排他锁(IX): 事务准备给数据行加入排他锁,事务在一个数据行加排他锁前必须先取得该表的IX锁。
注意:
这里的意向锁是表级锁,表示的是一种意向,仅仅表示事务正在读或写某一行记录,在真正加行锁时才会判断是否冲突。意向锁是InnoDB自动加的,不需要用户干预。
IX,IS是表级锁,不会和行级的X,S锁发生冲突,只会和表级的X,S发生冲突。
InnoDB的锁机制兼容情况如下:
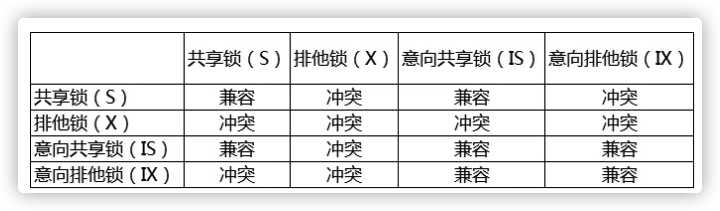
3、死锁和避免死锁
InnoDB的行级锁是基于索引实现的,如果查询语句为命中任何索引,用表级锁. 对索引加的锁,不针对数据记录,访问不同行记录,如用相同索引键仍锁冲突,
SELECT…LOCKINSHARE MODE 或 SELECT…FORUPDATE;
用锁时,如没有定义索引,InnoDB****创建隐藏聚簇索引加记录锁。
InnoDB锁逐步获得,两个事务都要获得对方持有的锁,都等待,产生死锁。 可检测到,并使一个事务释放锁回退,另一个获取锁完成事务,避免死锁:
(1)表级锁来减少死锁
(2)多个程序尽量相同顺序访问表(解决并发理论中哲学家就餐问题一种思路)
(3)同一个事务尽可能一次锁定所有资源。
4、总结与补充
页级锁: 介于行级锁和表级锁中间。表级锁速度快,但冲突多,行级冲突少,但速度慢。页级折衷,一次锁定相邻一组记录。BDB支持页级锁。开销和加锁时间界于表锁和行锁之间,会出现死锁。并发度一般。
Redis
下面是我总结的一些关于并发的小问题,你可以拿来自测:
一、Redis 和 Memcached 的区别和共同点
1.背景介绍
在大多数Web应用都将数据保存到关系型数据库中,WWW服务器从中读取数据并在浏览器中显示。但随着数据量的增大、访问的集中,就会出现关系型数据的负担加重、数据库响应缓慢、网站打开延迟等问题。
通过在内存中缓存数据库的查询结果,减少数据访问次数,以提高动态Web应用的速度,提高网站架构的并发能力和可扩展性
传统开发中用的数据库最多的就是MySQL了,随着数据量上千万或上亿级后,它的关系型数据库的读取速度可能并不能满足我们对数据的需求,所以内存式的缓存系统就出现了
2.知识剖析
Memcache 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
Memcache基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcache协议与守护进程通信。
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,应用数据量不能大于硬件内存。
在内存数据库方面的另一个优点是, 相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。
同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
3.常见问题
Redis与memcached有什么不同
什么是原子性,什么是原子性操作?
4.解决方案
Memcached
内部的数据存储,使用基于Slab的内存管理方式,有利于减少内存碎片和频繁分配销毁内存所带来的开销。各个Slab按需动态分配一个page的内存
(和4Kpage的概念不同,这里默认page为1M),page内部按照不同slab class的尺寸再划分为内存chunk供服务器存储KV键值对使用
Redis内部的数据结构最终也会落实到key-Value对应的形式,不过从暴露给用户的数据结构来看,
要比memcached丰富,除了标准的通常意义的键值对,Redis还支持List,Set, Hashes,Sorted Set等数据结构
基本命令
Memcached的命令或者说通讯协议非常简单,Server所支持的命令基本就是对特定key的添加,删除,替换,原子更新,读取等,具体包括 Set, Get, Add, Replace, Append, Inc/Dec 等等
Memcached的通讯协议包括文本格式和二进制格式,用于满足简单网络客户端工具(如telnet)和对性能要求更高的客户端的不同需求
Redis的命令在KV(String类型)上提供与Memcached类似的基本操作,在其它数据结构上也支持基本类似的操作(当然还有这些数据结构所特有的操作,如Set的union,List的pop等)而支持更多的数据结构,在一定程度上也就意味着更加广泛的应用场合
除了多种数据结构的支持,
Redis相比Memcached还提供了许多额外的特性,比如Subscribe/publish命令,以支持发布/订阅模式这样的通知机制等等,这些额外的特性同样有助于拓展它的应用场景Redis的客户端-服务器通讯协议完全采用文本格式(在将来可能的服务器间通讯会采用二进制格式)
分布式实现:
(1)memcached的分布式由客户端实现,通过一致性哈希算法来保证访问的缓存命中率;Redis的分布式由服务器端实现,通过服务端配置来实现分布式;
(2)事务性,memcached没有事务的概念,但是可以通过CAS协议来保证数据的完整性,一致性。Redis引入数据库中的事务概念来保证数据的完整性和一致性。
(3)简单性,memcached是纯KV缓存,协议简单,学习和使用成本比redis小很多
Memcached也不做数据的持久化工作,但是有许多基于memcached协议的项目实现了数据的持久化,例如memcacheDB使用BerkeleyDB进行数据存储,但本质上它已经不是一个Cache Server,而只是一个兼容Memcached的协议key-valueData Store了
Redis可以以master-slave的方式配置服务器,Slave节点对数据进行replica备份,Slave节点也可以充当Read only的节点分担数据读取的工作
Redis内建支持两种持久化方案,snapshot快照和AOF 增量Log方式。快照顾名思义就是隔一段时间将完整的数据Dump下来存储在文件中。AOF增量Log则是记录对数据的修改操作(实际上记录的就是每个对数据产生修改的命令本身).
二、为什么要用 Redis/为什么要用缓存?
简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
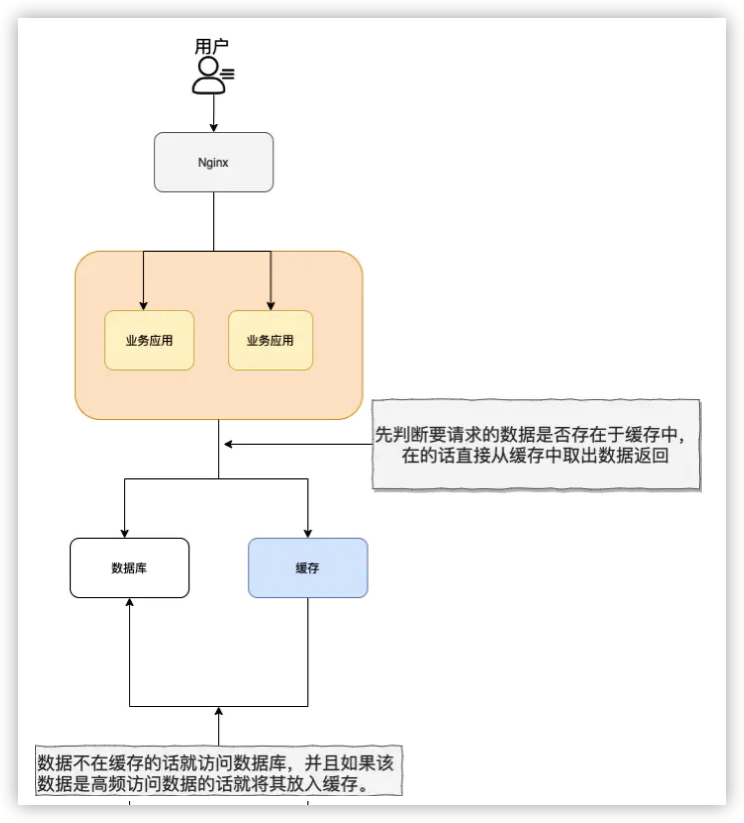
高性能 : 对照上面 假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。 这样有什么好处呢? 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。 不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
高并发: 一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。 QPS(Query Per Second):服务器每秒可以执行的查询次数; 所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发
三、Redis 常见数据结构以及使用场景分析
- string 1、介绍 :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 简单动态字符串(simple dynamic string,SDS)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。 2、常用命令: set,get,strlen,exists,dect,incr,setex 等等。 3、应用场景 :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。 下面我们简单看看它的使用!
普通字符串的基本操作:
127.0.0.1:6379> set key value #设置 key-value 类型的值
OK
127.0.0.1:6379> get key # 根据 key 获得对应的 value
"value"
127.0.0.1:6379> exists key # 判断某个 key 是否存在
(integer) 1
127.0.0.1:6379> strlen key # 返回 key 所储存的字符串值的长度。
(integer) 5
127.0.0.1:6379> del key # 删除某个 key 对应的值
(integer) 1
127.0.0.1:6379> get key
(nil)
批量设置 :
127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值
OK
127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
1) "value1"
2) "value2"Copy to clipboardErrorCopied
计数器(字符串的内容为整数的时候可以使用):
127.0.0.1:6379> set number 1
OK
127.0.0.1:6379> incr number # 将 key 中储存的数字值增一
(integer) 2
127.0.0.1:6379> get number
"2"
127.0.0.1:6379> decr number # 将 key 中储存的数字值减一
(integer) 1
127.0.0.1:6379> get number
"1"Copy to clipboardErrorCopied
过期:
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
(integer) 1
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
OK
127.0.0.1:6379> ttl key # 查看数据还有多久过期
(integer) 56
- list 1.介绍 :list 即是 链表。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 LinkedList,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 2.常用命令: rpush,lpop,lpush,rpop,lrange、llen 等。 3.应用场景: 发布与订阅或者说消息队列、慢查询。 下面我们简单看看它的使用
通过 rpush/lpop 实现队列:
127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
(integer) 1
127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
(integer) 3
127.0.0.1:6379> lpop myList # 将 list的尾部(最左边)元素取出
"value1"
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
1) "value2"
2) "value3"
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
1) "value2"
2) "value3"Copy to clipboardErrorCopied
通过 rpush/rpop 实现栈:
127.0.0.1:6379> rpush myList2 value1 value2 value3
(integer) 3
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
"value3"Copy to clipboardErrorCopied
我专门花了一个图方便小伙伴们来理解:
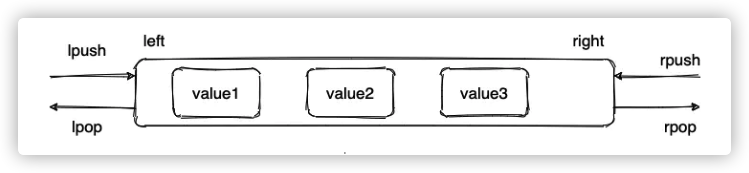
通过 lrange 查看对应下标范围的列表元素:
127.0.0.1:6379> rpush myList value1 value2 value3
(integer) 3
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
1) "value1"
2) "value2"
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
1) "value1"
2) "value2"
3) "value3"Copy to clipboardErrorCopied
通过 lrange 命令,你可以基于 list 实现分页查询,性能非常高!
通过 llen 查看链表长度:
127.0.0.1:6379> llen myList
(integer) 3
- hash
- 介绍 :hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
- 常用命令: hset,hmset,hexists,hget,hgetall,hkeys,hvals 等。
- 应用场景: 系统中对象数据的存储。 下面我们简单看看它的使用!
127.0.0.1:6379> hset userInfoKey name "guide" description "dev" age "24"
OK
127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
(integer) 1
127.0.0.1:6379> hget userInfoKey name # 获取存储在哈希表中指定字段的值。
"guide"
127.0.0.1:6379> hget userInfoKey age
"24"
127.0.0.1:6379> hgetall userInfoKey # 获取在哈希表中指定 key 的所有字段和值
1) "name"
2) "guide"
3) "description"
4) "dev"
5) "age"
6) "24"
127.0.0.1:6379> hkeys userInfoKey # 获取 key 列表
1) "name"
2) "description"
3) "age"
127.0.0.1:6379> hvals userInfoKey # 获取 value 列表
1) "guide"
2) "dev"
3) "24"
127.0.0.1:6379> hset userInfoKey name "GuideGeGe" # 修改某个字段对应的值
127.0.0.1:6379> hget userInfoKey name
"GuideGeGe"
- Set 1.介绍 : set 类似于 Java 中的 HashSet 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。 2.常用命令: sadd,spop,smembers,sismember,scard,sinterstore,sunion 等。 3.应用场景: 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景 下面我们简单看看它的使用!
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
(integer) 2
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
(integer) 0
127.0.0.1:6379> smembers mySet # 查看 set 中所有的元素
1) "value1"
2) "value2"
127.0.0.1:6379> scard mySet # 查看 set 的长度
(integer) 2
127.0.0.1:6379> sismember mySet value1 # 检查某个元素是否存在set 中,只能接收单个元素
(integer) 1
127.0.0.1:6379> sadd mySet2 value2 value3
(integer) 2
127.0.0.1:6379> sinterstore mySet3 mySet mySet2 # 获取 mySet 和 mySet2 的交集并存放在 mySet3 中
(integer) 1
127.0.0.1:6379> smembers mySet3
1) "value2"
- sorted set 1.介绍: 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。 2.常用命令: zadd,zcard,zscore,zrange,zrevrange,zrem 等。 3.应用场景: 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。 下面我们简单看看它的使用!
127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
(integer) 1
127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
(integer) 2
127.0.0.1:6379> zcard myZset # 查看 sorted set 中的元素数量
(integer) 3
127.0.0.1:6379> zscore myZset value1 # 查看某个 value 的权重
"3"
127.0.0.1:6379> zrange myZset 0 -1 # 顺序输出某个范围区间的元素,0 -1 表示输出所有元素
1) "value3"
2) "value2"
3) "value1"
127.0.0.1:6379> zrange myZset 0 1 # 顺序输出某个范围区间的元素,0 为 start 1 为 stop
1) "value3"
2) "value2"
127.0.0.1:6379> zrevrange myZset 0 1 # 逆序输出某个范围区间的元素,0 为 start 1 为 stop
1) "value1"
2) "value2"
四、Redis 没有使用多线程?为什么不使用多线程?Redis6.0 之后为何引入了多线程?
Redis 6.0 新特性,多线程连环 13 问!
Redis 6.0 来了
—
在全国一片祥和IT民工欢度五一节假日的时候,Redis 6.0不声不响地于5 月 2 日正式发布了,吓得我赶紧从床上爬起来,学无止境!学无止境!
对于6.0版本,Redis之父Antirez在RC1版本发布时(2019-12-19)在他的博客上连续用了几个“EST”词语来评价:
the most “enterprise” Redis version to date // 最”企业级”的
the largest release of Redis ever as far as I can tell // 最大的
the one where the biggest amount of people participated // 参与人数最多的
这个版本提供了诸多令人心动的新特性及功能改进,比如新网络协议RESP3,新的集群代理,ACL等,其中关注度最高的应该是“多线程”了,笔者也第一时间体验了一下,带着众多疑问,我们来一起开始“Redis 6.0 新特性-多线程连环13问”。
Redis 6.0 多线程连环13问
—
1.Redis6.0之前的版本真的是单线程吗?
Redis在处理客户端的请求时,包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。
但如果严格来讲从Redis4.0之后并不是单线程,除了主线程外,它也有后台线程在处理一些较为缓慢的操作,例如清理脏数据、无用连接的释放、大 key 的删除等等。
2.Redis6.0之前为什么一直不使用多线程?
官方曾做过类似问题的回复:使用Redis时,几乎不存在CPU成为瓶颈的情况, Redis主要受限于内存和网络。例如在一个普通的Linux系统上,Redis通过使用pipelining每秒可以处理100万个请求,所以如果应用程序主要使用O(N)或O(log(N))的命令,它几乎不会占用太多CPU。
使用了单线程后,可维护性高。多线程模型虽然在某些方面表现优异,但是它却引入了程序执行顺序的不确定性,带来了并发读写的一系列问题,增加了系统复杂度、同时可能存在线程切换、甚至加锁解锁、死锁造成的性能损耗。
Redis通过AE事件模型以及IO多路复用等技术,处理性能非常高,因此没有必要使用多线程。单线程机制使得 Redis 内部实现的复杂度大大降低,Hash 的惰性 Rehash、Lpush 等等 “线程不安全” 的命令都可以无锁进行。
3.Redis6.0为什么要引入多线程呢?
Redis将所有数据放在内存中,内存的响应时长大约为100纳秒,对于小数据包,Redis服务器可以处理80,000到100,000 QPS,这也是Redis处理的极限了,对于80%的公司来说,单线程的Redis已经足够使用了。
但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的QPS。常见的解决方案是在分布式架构中对数据进行分区并采用多个服务器,但该方案有非常大的缺点,例如要管理的Redis服务器太多,维护代价大;某些适用于单个Redis服务器的命令不适用于数据分区;数据分区无法解决热点读/写问题;数据偏斜,重新分配和放大/缩小变得更加复杂等等。
从Redis自身角度来说,因为读写网络的read/write系统调用占用了Redis执行期间大部分CPU时间,瓶颈主要在于网络的 IO 消耗, 优化主要有两个方向:
• 提高网络 IO 性能,典型的实现比如使用 DPDK 来替代内核网络栈的方式
• 使用多线程充分利用多核,典型的实现比如 Memcached。
协议栈优化的这种方式跟 Redis 关系不大,支持多线程是一种最有效最便捷的操作方式。所以总结起来,redis支持多线程主要就是两个原因:
• 可以充分利用服务器 CPU 资源,目前主线程只能利用一个核
• 多线程任务可以分摊 Redis 同步 IO 读写负荷
4.Redis6.0默认是否开启了多线程?
Redis6.0的多线程默认是禁用的,只使用主线程。如需开启需要修改redis.conf配置文件:io-threads-do-reads yes
5.Redis6.0多线程开启时,线程数如何设置?
开启多线程后,还需要设置线程数,否则是不生效的。同样修改redis.conf配置文件
关于线程数的设置,官方有一个建议:4核的机器建议设置为2或3个线程,8核的建议设置为6个线程,线程数一定要小于机器核数。还需要注意的是,线程数并不是越大越好,官方认为超过了8个基本就没什么意义了。
6.Redis6.0采用多线程后,性能的提升效果如何?
Redis 作者 antirez 在 RedisConf 2019分享时曾提到:Redis 6 引入的多线程 IO 特性对性能提升至少是一倍以上。国内也有大牛曾使用unstable版本在阿里云esc进行过测试,GET/SET 命令在4线程 IO时性能相比单线程是几乎是翻倍了。
测试环境:
Redis Server: 阿里云 Ubuntu 18.04,8 CPU 2.5 GHZ, 8G 内存,主机型号 ecs.ic5.2xlarge
Redis Benchmark Client: 阿里云 Ubuntu 18.04,8 2.5 GHZ CPU, 8G 内存,主机型号 ecs.ic5.2xlarge
测试结果:
说明1:这些性能验证的测试并没有针对严谨的延时控制和不同并发的场景进行压测。数据仅供验证参考而不能作为线上指标。
说明2:如果开启多线程,至少要4核的机器,且Redis实例已经占用相当大的CPU耗时的时候才建议采用,否则使用多线程没有意义。所以估计80%的公司开发人员看看就好。
7.Redis6.0多线程的实现机制?
流程简述如下:
1、主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列
2、主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程
3、主线程阻塞等待 IO 线程读取 socket 完毕
4、主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行
5、主线程阻塞等待 IO 线程将数据回写 socket 完毕
6、解除绑定,清空等待队列
该设计有如下特点:
1、IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
2、IO 线程只负责读写 socket 解析命令,不负责命令处理
8.开启多线程后,是否会存在线程并发安全问题?
从上面的实现机制可以看出,Redis的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程顺序执行。所以我们不需要去考虑控制 key、lua、事务,LPUSH/LPOP 等等的并发及线程安全问题。
9.Linux环境上如何安装Redis6.0.1(6.0的正式版是6.0.1)?
这个和安装其他版本的redis没有任何区别,整个流程跑下来也没有任何的坑,所以这里就不做描述了。唯一要注意的就是配置多线程数一定要小于cpu的核心数,查看核心数量命令:
[root@centos7.5 ~]# lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 4On-line CPU(s) list: 0-3
10.Redis6.0的多线程和Memcached多线程模型进行对比
前些年memcached 是各大互联网公司常用的缓存方案,因此redis 和 memcached 的区别基本成了面试官缓存方面必问的面试题,最近几年memcached用的少了,基本都是 redis。
不过随着Redis6.0加入了多线程特性,类似的问题可能还会出现,接下来我们只针对多线程模型来简单比较一下。
如上图所示:Memcached 服务器采用 master-woker 模式进行工作,服务端采用 socket 与客户端通讯。主线程、工作线程 采用 pipe管道进行通讯。主线程采用 libevent 监听 listen、accept 的读事件,事件响应后将连接信息的数据结构封装起来,根据算法选择合适的工作线程,将连接任务携带连接信息分发出去,相应的线程利用连接描述符建立与客户端的socket连接 并进行后续的存取数据操作。
Redis6.0与Memcached多线程模型对比:
相同点:都采用了 master线程-worker 线程的模型
不同点:Memcached 执行主逻辑也是在 worker 线程里,模型更加简单,实现了真正的线程隔离,符合我们对线程隔离的常规理解。而 Redis 把处理逻辑交还给 master 线程,虽然一定程度上增加了模型复杂度,但也解决了线程并发安全等问题。
11.Redis作者是如何点评 “多线程”这个新特性的?
关于多线程这个特性,在6.0 RC1时,Antirez曾做过说明:
Redis支持多线程有2种可行的方式:第一种就是像“memcached”那样,一个Redis实例开启多个线程,从而提升GET/SET等简单命令中每秒可以执行的操作。这涉及到I/O、命令解析等多线程处理,因此,我们将其称之为“I/O threading”。另一种就是允许在不同的线程中执行较耗时较慢的命令,以确保其它客户端不被阻塞,我们将这种线程模型称为“Slow commands threading”。
经过深思熟虑,Redis不会采用“I/O threading”,redis在运行时主要受制于网络和内存,所以提升redis性能主要是通过在多个redis实例,特别是redis集群。接下来我们主要会考虑改进两个方面:
\1. Redis集群的多个实例通过编排能够合理地使用本地实例的磁盘,避免同时重写AOF。
2.提供一个Redis集群代理,便于用户在没有较好的集群协议客户端时抽象出一个集群。
补充说明一下,Redis和memcached一样是一个内存系统,但不同于Memcached。多线程是复杂的,必须考虑使用简单的数据模型,执行LPUSH的线程需要服务其他执行LPOP的线程。
我真正期望的实际是“slow operations threading”,在redis6或redis7中,将提供“key-level locking”,使得线程可以完全获得对键的控制以处理缓慢的操作。
12.Redis线程中经常提到IO多路复用,如何理解?
这是IO模型的一种,即经典的Reactor设计模式,有时也称为异步阻塞IO。
多路指的是多个socket连接,复用指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
五、Redis 给缓存数据设置过期时间有啥用?
六、Redis 是如何判断数据是否过期的呢?
七、过期的数据的删除策略了解么?
定时删除
定时删除是指在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作。
定时删除策略对内存是最友好的:通过使用定时器,定时删除策略可以保证过期键会尽可能快的被删除,并释放过期键所占用的内存。
定时删除策略的缺点是,他对CPU时间是最不友好的:再过期键比较多的情况下,删除过期键这一行为可能会占用相当一部分CPU时间。
除此之外,创建一个定时器需要用到Redis服务器中的时间事件。而当前时间事件的实现方式—-无序链表,查找一个事件的时间复杂度为O(N)—-并不能高效地处理大量时间事件。
惰性删除
惰性删除是指放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话就删除该键,如果没有过期就返回该键。
惰性删除策略对CPU时间来说是最友好的,但对内存是最不友好的。如果数据库中有非常多的过期键,而这些过期键又恰好没有被访问到的话,那么他们也许永远也不会被删除。
定期删除
定期删除是指每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。
定期删除策略是前两种策略的一种整合和折中:
- 定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
- 除此之外,通过定期删除过期键,定期删除策略有效地减少了因为过期键带来的内存浪费。
定期删除策略的难点是确定删除操作执行的时长和频率:
- 如果删除操作执行的太频繁或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将CPU时间过多的消耗在删除过期键上面。
- 如果删除操作执行的太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
Redis的过期键删除策略
Redis服务器实际使用的是惰性删除和定期删除两种策略:通过配合使用这两种删除策略,服务器可以很好的在合理使用CPU时间和避免浪费内存空间之间取得平衡。
定期删除策略的实现
过期键的定期删除策略由函数redis.c/activeExpireCycle实现,每当Redis服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用,它在规定的时间内分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
八、Redis 内存淘汰机制了解么?
内存淘汰策略
内存淘汰只是 Redis 提供的一个功能,为了更好地实现这个功能,必须为不同的应用场景提供不同的策略,内存淘汰策略讲的是为实现内存淘汰我们具体怎么做,要解决的问题包括淘汰键空间如何选择?在键空间中淘汰键如何选择?
Redis 提供了下面几种淘汰策略供用户选择,其中默认的策略为 noeviction 策略:
- noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错
- allkeys-lru:在主键空间中,优先移除最近未使用的key
- volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的 key
- allkeys-random:在主键空间中,随机移除某个 key
- volatile-random:在设置了过期时间的键空间中,随机移除某个 key
- volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的 key 优先移除
这里补充一下主键空间和设置了过期时间的键空间,举个例子,假设我们有一批键存储在Redis中,则有那么一个哈希表用于存储这批键及其值,如果这批键中有一部分设置了过期时间,那么这批键还会被存储到另外一个哈希表中,这个哈希表中的值对应的是键被设置的过期时间。设置了过期时间的键空间为主键空间的子集。
如何选择淘汰策略
我们了解了 Redis 大概提供了这么几种淘汰策略,那么如何选择呢?淘汰策略的选择可以通过下面的配置指定:
# maxmemory-policy noeviction
但是这个值填什么呢?为解决这个问题,我们需要了解我们的应用请求对于 Redis 中存储的数据集的访问方式以及我们的诉求是什么。同时 Redis 也支持 Runtime 修改淘汰策略,这使得我们不需要重启 Redis 实例而实时的调整内存淘汰策略。
下面看看几种策略的适用场景:
- allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择 allkeys-lru 策略
- allkeys-random:如果我们的应用对于缓存 key 的访问概率相等,则可以使用这个策略
- volatile-ttl:这种策略使得我们可以向 Redis 提示哪些 key 更适合被 eviction
另外,volatile-lru 策略和 volatile-random 策略适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个 Redis 实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用 allkeys-lru 策略从而更有效率的使用内存。
非精准的 LRU
上面提到的 LRU(Least Recently Used)策略,实际上 Redis 实现的 LRU 并不是可靠的 LRU,也就是名义上我们使用 LRU 算法淘汰键,但是实际上被淘汰的键并不一定是真正的最久没用的,这里涉及到一个权衡的问题,如果需要在全部键空间内搜索最优解,则必然会增加系统的开销,Redis 是单线程的,也就是同一个实例在每一个时刻只能服务于一个客户端,所以耗时的操作一定要谨慎。为了在一定成本内实现相对的 LRU,早期的 Redis 版本是基于采样的 LRU,也就是放弃全部键空间内搜索解改为采样空间搜索最优解。自从 Redis3.0 版本之后,Redis 作者对于基于采样的 LRU 进行了一些优化,目的是在一定的成本内让结果更靠近真实的 LRU。
九、Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
Redis是常用的基于内存的缓存服务,能为我们缓存数据减少数据库访问从而提升性能,也能作为NoSQL数据库存储数据或借助有序队列做排队系统等。当仅作为数据缓存用时,Redis服务的可用性要求没那么高, 毕竟挂了还能从数据库获取, 但如果作为数据库或队列使用时,Redis挂了可能会影响到业务。本文整理了Redis的持久化方案,使用它们来对Redis的内存数据进行持久化,保障数据的安全性。
Redis支持RDB与AOF两种持久化机制,持久化可以避免因进程异常退出或down机导致的数据丢失问题,在下次重启时能利用之前的持久化文件实现数据恢复。
RDB持久化
RDB持久化即通过创建快照(压缩的二进制文件)的方式进行持久化,保存某个时间点的全量数据。RDB持久化是Redis默认的持久化方式。RDB持久化的触发包括手动触发与自动触发两种方式。
手动触发
- save, 在命令行执行save命令,将以同步的方式创建rdb文件保存快照,会阻塞服务器的主进程,生产环境中不要用
- bgsave, 在命令行执行bgsave命令,将通过fork一个子进程以异步的方式创建rdb文件保存快照,除了fork时有阻塞,子进程在创建rdb文件时,主进程可继续处理请求
自动触发
- 在redis.conf中配置
save m n定时触发,如save 900 1表示在900s内至少存在一次更新就触发 - 主从复制时,如果从节点执行全量复制操作,主节点自动执行bgsave生成RDB文件并发送给从节点
- 执行debug reload命令重新加载Redis时
- 执行shutdown且没有开启AOF持久化
redis.conf中RDB持久化配置
# 只要满足下列条件之一,则会执行bgsave命令
save 900 1 # 在900s内存在至少一次写操作
save 300 10
save 60 10000
# 禁用RBD持久化,可在最后加 save ""
# 当备份进程出错时主进程是否停止写入操作
stop-writes-on-bgsave-error yes
# 是否压缩rdb文件 推荐no 相对于硬盘成本cpu资源更贵
rdbcompression no
AOF持久化
AOF(Append-Only-File)持久化即记录所有变更数据库状态的指令,以append的形式追加保存到AOF文件中。在服务器下次启动时,就可以通过载入和执行AOF文件中保存的命令,来还原服务器关闭前的数据库状态。
redis.conf中AOF持久化配置如下
# 默认关闭AOF,若要开启将no改为yes
appendonly no
# append文件的名字
appendfilename "appendonly.aof"
# 每隔一秒将缓存区内容写入文件 默认开启的写入方式
appendfsync everysec
# 当AOF文件大小的增长率大于该配置项时自动开启重写(这里指超过原大小的100%)。
auto-aof-rewrite-percentage 100
# 当AOF文件大小大于该配置项时自动开启重写
auto-aof-rewrite-min-size 64mb
AOF持久化的实现包括3个步骤:
- 命令追加:将命令追加到AOF缓冲区
- 文件写入:缓冲区内容写到AOF文件
- 文件保存:AOF文件保存到磁盘
其中后两步的频率通过appendfsync来配置,appendfsync的选项包括
- always, 每执行一个命令就保存一次,安全性最高,最多只丢失一个命令的数据,但是性能也最低(频繁的磁盘IO)
- everysec,每一秒保存一次,推荐使用,在安全性与性能之间折中,最多丢失一秒的数据
- no, 依赖操作系统来执行(一般大概30s一次的样子),安全性最低,性能最高,丢失操作系统最后一次对AOF文件触发SAVE操作之后的数据
AOF通过保存命令来持久化,随着时间的推移,AOF文件会越来越大,Redis通过AOF文件重写来解决AOF文件不断增大的问题(可以减少文件的磁盘占有量,加快数据恢复的速度),原理如下:
- 调用fork,创建一个子进程
- 子进程读取当前数据库的状态来“重写”一个新的AOF文件(这里虽然叫“重写”,但实际并没有对旧文件进行任何读取,而是根据数据库的当前状态来形成指令)
- 主进程持续将新的变动同时写到AOF重写缓冲区与原来的AOF缓冲区中
- 主进程获取到子进程重写AOF完成的信号,调用信号处理函数将AOF重写缓冲区内容写入新的AOF文件中,并对新文件进行重命名,原子地覆盖原有AOF文件,完成新旧文件的替换
AOF的重写也分为手动触发与自动触发
- 手动触发:直接调用bgrewriteaof命令
- 自动触发:根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定自动触发时机。其中auto-aof-rewrite-min-size表示运行AOF重写时文件最小体积,默认为64MB。auto-aof-rewrite-percentage表示当前AOF文件大小(aof_current_size)和上一次重写后AOF文件大小(aof_base_size)的比值。自动触发时机为 aof_current_size > auto-aof-rewrite-min-size &&(aof_current_size - aof_base_size)/aof_base_size> = auto-aof-rewrite-percentage
RDB vs AOF
RDB与AOF两种方式各有优缺点。
RDB的优点:与AOF相比,RDB文件相对较小,恢复数据比较快(原因见数据恢复部分) RDB的缺点:服务器宕机,RBD方式会丢失掉上一次RDB持久化后的数据;使用bgsave fork子进程时会耗费内存。
AOF的优点:AOF只是追加文件,对服务器性能影响较小,速度比RDB快,消耗内存也少,同时可读性高。 AOF的缺点:生成的文件相对较大,即使通过AOF重写,仍然会比较大;恢复数据的速度比RDB慢。
数据库的恢复
服务器启动时,如果没有开启AOF持久化功能,则会自动载入RDB文件,期间会阻塞主进程。如果开启了AOF持久化功能,服务器则会优先使用AOF文件来还原数据库状态,因为AOF文件的更新频率通常比RDB文件的更新频率高,保存的数据更完整。
redis数据库恢复的处理流程如下,
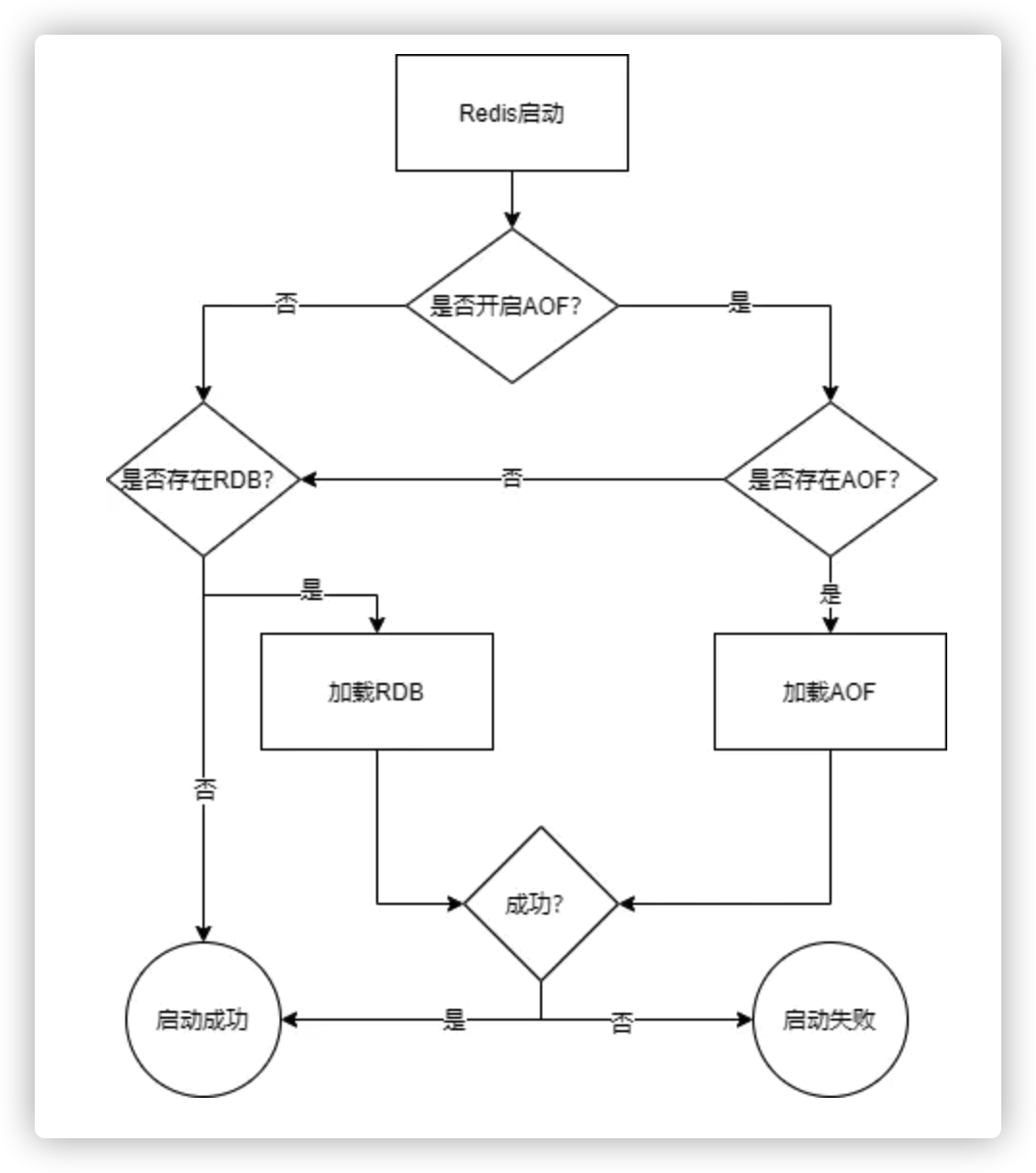
在数据恢复方面,RDB的启动时间会更短,原因有两个:
- RDB 文件中每一条数据只有一条记录,不会像AOF日志那样可能有一条数据的多次操作记录。所以每条数据只需要写一次就行了,文件相对较小。
- RDB 文件的存储格式和Redis数据在内存中的编码格式是一致的,不需要再进行数据编码工作,所以在CPU消耗上要远小于AOF日志的加载。
但是在进行RDB持久化时,fork出来进行dump操作的子进程会占用与父进程一样的内存,采用的copy-on-write机制,对性能的影响和内存的消耗都是比较大的。比如16G内存,Redis已经使用了10G,这时save的话会再生成10G,变成20G,大于系统的16G。这时候会发生交换,要是虚拟内存不够则会崩溃,导致数据丢失。所以在用redis的时候一定对系统内存做好容量规划。
RDB、AOF混合持久化
Redis从4.0版开始支持RDB与AOF的混合持久化方案。首先由RDB定期完成内存快照的备份,然后再由AOF完成两次RDB之间的数据备份,由这两部分共同构成持久化文件。该方案的优点是充分利用了RDB加载快、备份文件小及AOF尽可能不丢数据的特性。缺点是兼容性差,一旦开启了混合持久化,在4.0之前的版本都不识别该持久化文件,同时由于前部分是RDB格式,阅读性较低。
开启混合持久化
aof-use-rdb-preamble yes
数据恢复加载过程就是先按照RDB进行加载,然后把AOF命令追加写入。
持久化方案的建议
- 如果Redis只是用来做缓存服务器,比如数据库查询数据后缓存,那可以不用考虑持久化,因为缓存服务失效还能再从数据库获取恢复。
- 如果你要想提供很高的数据保障性,那么建议你同时使用两种持久化方式。如果你可以接受灾难带来的几分钟的数据丢失,那么可以仅使用RDB。
- 通常的设计思路是利用主从复制机制来弥补持久化时性能上的影响。即Master上RDB、AOF都不做,保证Master的读写性能,而Slave上则同时开启RDB和AOF(或4.0以上版本的混合持久化方式)来进行持久化,保证数据的安全性。
十、Redis 缓存穿透、缓存雪崩?
1. 缓存穿透
通过某个key比如A进行查询时,每次都不能从缓存中获取到数据,因此每次都是访问数据库进行查询(数据库中也没有)。
解决方案 当key值A从数据库未查询到数据时,在缓存中将A的值设为空并设置过期时间。
2. 缓存击穿
某个热点key A在高并发的请求的情况下,缓存失效的瞬间,大量请求击穿缓存访问数据库。
解决方案
- 1.业务允许的情况下,热点数据不过期;
- 2.构建互斥锁,在第一个请求创建完成缓存后再释放锁,从而其他请求可以通过key访问缓存;
3. 缓存雪崩
雪崩是指缓存中大量数据过期导致系统涌入大量查询请求时,因大部分数据在Redis层已经失效,请求渗透到数据库层,大批量请求引起数据库压力造成查询堵塞甚至宕机。
代码层面,设置数据过期时间:
- 1.数据失效时间分散,不要在同一个时间大量缓存数据失效;
- 2.业务允许的情况下,数据不失效;
架构层面:
- 1.redis高可用,Redis Cluster,主从同步,避免redis全盘奔溃;
- 2.缓存分级,ehcache + redis + mysql模式,本地内存中无数据再从redis中查找;再者,MySQL实现限流和降级,避免宕机。
- 3.redis必须要持久化,重启后从磁盘加载数据,快速恢复缓存数据;
十一、如何保证缓存和数据库数据的一致性?
看到好些人在写更新缓存数据代码时,先删除缓存,然后再更新数据库,而后续的操作会把数据再装载的缓存中。然而,这个是逻辑是错误的。试想,两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的,而且还一直这样脏下去了。
这篇文章说一下几个缓存更新的Design Pattern(让我们多一些套路吧)。
这里,我们先不讨论更新缓存和更新数据这两个事是一个事务的事,或是会有失败的可能,我们先假设更新数据库和更新缓存都可以成功的情况(我们先把成功的代码逻辑先写对)。
更新缓存的的Design Pattern有四种:
- Cache aside (旁路缓存 )
- Read through
- Write through
- Write behind caching
Cache Aside Pattern
这是最常用最常用的pattern了。其具体逻辑如下:
- **失效:**应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- **命中:**应用程序从cache中取数据,取到后返回。
- **更新:**先把数据存到数据库中,成功后,再让缓存失效。
注意,我们的更新是先更新数据库,成功后,让缓存失效。那么,这种方式是否可以没有文章前面提到过的那个问题呢?我们可以脑补一下。
一个是查询操作,一个是更新操作的并发,首先,没有了删除cache数据的操作了,而是先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会像文章开头的那个逻辑产生的问题,后续的查询操作一直都在取老的数据。
这是标准的design pattern,包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。为什么不是写完数据库后更新缓存?你可以看一下Quora上的这个问答《Why does Facebook use delete to remove the key-value pair in Memcached instead of updating the Memcached during write request to the backend?》,主要是怕两个并发的写操作导致脏数据。
那么,是不是Cache Aside这个就不会有并发问题了?不是的,比如,一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
但,这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,这也就是Quora上的那个答案里说的,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间。
Read/Write Through Pattern
我们可以看到,在上面的Cache Aside套路中,我们的应用代码需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository)。所以,应用程序比较啰嗦。而Read/Write Through套路是把更新数据库(Repository)的操作由缓存自己代理了,所以,对于应用层来说,就简单很多了。可以理解为,应用认为后端就是一个单一的存储,而存储自己维护自己的Cache。
Read Through
Read Through 套路就是在查询操作中更新缓存,也就是说,当缓存失效的时候(过期或LRU换出),Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。
Write Through
Write Through 套路和Read Through相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库(这是一个同步操作) 下图自来Wikipedia的Cache词条。其中的Memory你可以理解为就是我们例子里的数据库。
Write Behind Caching Pattern
Write Behind 又叫 Write Back。**一些了解Linux操作系统内核的同学对write back应该非常熟悉,这不就是Linux文件系统的Page Cache的算法吗?是的,你看基础这玩意全都是相通的。**所以,基础很重要,我已经不是一次说过基础很重要这事了。
Write Back套路,一句说就是,在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。这个设计的好处就是让数据的I/O操作飞快无比(因为直接操作内存嘛 ),因为异步,write backg还可以合并对同一个数据的多次操作,所以性能的提高是相当可观的。
但是,其带来的问题是,数据不是强一致性的,而且可能会丢失(我们知道Unix/Linux非正常关机会导致数据丢失,就是因为这个事)。在软件设计上,我们基本上不可能做出一个没有缺陷的设计,就像算法设计中的时间换空间,空间换时间一个道理,有时候,强一致性和高性能,高可用和高性性是有冲突的。软件设计从来都是取舍Trade-Off。
另外,Write Back实现逻辑比较复杂,因为他需要track有哪数据是被更新了的,需要刷到持久层上。操作系统的write back会在仅当这个cache需要失效的时候,才会被真正持久起来,比如,内存不够了,或是进程退出了等情况,这又叫lazy write。
在wikipedia上有一张write back的流程图,基本逻辑如下:
再多唠叨一些
1)上面讲的这些Design Pattern,其实并不是软件架构里的mysql数据库和memcache/redis的更新策略,这些东西都是计算机体系结构里的设计,比如CPU的缓存,硬盘文件系统中的缓存,硬盘上的缓存,数据库中的缓存。基本上来说,这些缓存更新的设计模式都是非常老古董的,而且历经长时间考验的策略,所以这也就是,工程学上所谓的Best Practice,遵从就好了。
2)有时候,我们觉得能做宏观的系统架构的人一定是很有经验的,其实,宏观系统架构中的很多设计都来源于这些微观的东西。比如,云计算中的很多虚拟化技术的原理,和传统的虚拟内存不是很像么?Unix下的那些I/O模型,也放大到了架构里的同步异步的模型,还有Unix发明的管道不就是数据流式计算架构吗?TCP的好些设计也用在不同系统间的通讯中,仔细看看这些微观层面,你会发现有很多设计都非常精妙……所以,请允许我在这里放句观点鲜明的话——如果你要做好架构,首先你得把计算机体系结构以及很多老古董的基础技术吃透了。
3)在软件开发或设计中,我非常建议在之前先去参考一下已有的设计和思路,看看相应的guideline,best practice或design pattern,吃透了已有的这些东西,再决定是否要重新发明轮子。千万不要似是而非地,想当然的做软件设计。
4)上面,我们没有考虑缓存(Cache)和持久层(Repository)的整体事务的问题。比如,更新Cache成功,更新数据库失败了怎么吗?或是反过来。关于这个事,如果你需要强一致性,你需要使用“两阶段提交协议”——prepare, commit/rollback,比如Java 7 的XAResource,还有MySQL 5.7的 XA Transaction,有些cache也支持XA,比如EhCache。当然,XA这样的强一致性的玩法会导致性能下降,关于分布式的事务的相关话题,你可以看看《分布式系统的事务处理》一文。
常用工具
非常重要!非常重要!特别是 Git 和 Docker。
Docker
传统的开发流程中,我们的项目通常需要使用 MySQL、Redis、FastDFS 等等环境,这些环境都是需要我们手动去进行下载并配置的,安装配置流程极其复杂,而且不同系统下的操作也不一样。
Docker 的出现完美地解决了这一问题,我们可以在容器中安装 MySQL、Redis 等软件环境,使得应用和环境架构分开,它的优势在于:
- 一致的运行环境,能够更轻松地迁移
- 对进程进行封装隔离,容器与容器之间互不影响,更高效地利用系统资源
- 可以通过镜像复制多个一致的容器
Docker 常见概念解读,可以看这篇 Github 上开源的这篇《Docker 基本概念解读》 ,从零到上手实战可以看《Docker 从入门到上手干事》这篇文章,内容非常详细!
另外,再给大家推荐一本质量非常高的开源书籍《Docker 从入门到实践》 ,这本书的内容非常新,毕竟书籍的内容是开源的,可以随时改进。
常用框架
Spring/SpringBoot
Spring 和 SpringBoot 真的很重要!
一定要搞懂 AOP 和 IOC 这两个概念。Spring 中 bean 的作用域与生命周期、SpringMVC 工作原理详解等等知识点都是非常重要的,一定要搞懂。
企业中做 Java 后端,你一定离不开 SpringBoot ,这个是必备的技能了!一定一定一定要学好!
像 SpringBoot 和一些常见技术的整合你也要知识怎么做,比如 SpringBoot 整合 MyBatis、 ElasticSearch、SpringSecurity、Redis 等等。
学习 Spring 的话,可以多看看 《Spring 的官方文档》,写的很详细。你可以在这里找到 Spring 全家桶的学习资源。
你也可以把 《Spring 实战》 这本书作为学习 Spring 的参考资料。 这本书还是比较新的,目前已经出到了第 5 版,基于 Spring 5 来讲。


了解了 Spring 中的一些常见概念和基本用法之后,你就可以开始学习 Spring Boot 了。
当然了,Spring 其实并不是学习 Spring Boot 的前置基础,相比于 Spring 来说,Spring Boot 要更容易上手一些!如果你只是想使用 Spring Boot 来做项目的话,直接学 Spring Boot 就可以了。
不过,我建议你在学习 Spring Boot 之前,可以看看 《Spring 常见问题总结》 。这些问题都是 Spring 比较重要的知识点,也是面试中经常会被问到的。
学习 Spring Boot 的话,还是建议可以多看看 《Spring Boot 的官方文档》,写的很详细。
你也可以把 《Spring Boot 实战》 这本书作为学习 Spring Boot 的参考资料。


这本书的整体质量实际一般,你当做参考书来看就好了!
相比于 《Spring Boot 实战》这本书,我更推荐国人写的 《Spring Boot 实战派》 。


这本书使用的 Spring Boot 2.0+的版本,还算比较新。整本书采用“知识点+实例”的形式编写,书籍的最后两章还有 2 个综合性的企业实战项目:
- 开发企业级通用的后台系统
- 实现一个类似“京东”的电子商务商城
作者在注意实战的过程中还不忘记对于一些重要的基础知识的讲解。
如果你想专研 Spring Boot 底层原理的话,可以看看 《Spring Boot 编程思想(核心篇)》 。


这本书稍微有点啰嗦,不过,原理介绍的比较清楚(不适合初学者)。
如果你比较喜欢看视频的话,推荐尚硅谷雷神的**《2021 版 Spring Boot2 零基础入门》** 。
这可能是全网质量最高并且免费的 Spring Boot 教程了,好评爆炸!
另外,Spring Boot 这块还有很多优质的开源教程,我已经整理好放到 awesome-java@SpringBoot 中了。


Netty
但凡涉及到网络通信就必然必然离不开网络编程。 Netty 目前作为 Java 网络编程最热门的框架,毫不夸张地说是每个 Java 程序员必备的技能之一。
为什么说学好 Netty 很有必要呢?
- Netty 基于 NIO (NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO )。使用 Netty 可以极大地简化并简化了 TCP 和 UDP 套接字服务器等网络编程,并且性能以及安全性等很多方面都非常优秀。
- 我们平常经常接触的 Dubbo、RocketMQ、Elasticsearch、gRPC、Spark、Elasticsearch 等等热门开源项目都用到了 Netty。
- 大部分微服务框架底层涉及到网络通信的部分都是基于 Netty 来做的,比如说 Spring Cloud 生态系统中的网关 Spring Cloud Gateway 。
下面是一些比较推荐的书籍/专栏。


这本书可以用来入门 Netty ,内容从 BIO 聊到了 NIO、之后才详细介绍为什么有 Netty 、Netty 为什么好用以及 Netty 重要的知识点讲解。
这本书基本把 Netty 一些重要的知识点都介绍到了,而且基本都是通过实战的形式讲解。
《Netty 进阶之路:跟着案例学 Netty》


内容都是关于使用 Netty 的实践案例比如内存泄露这些东西。如果你觉得你的 Netty 已经完全入门了,并且你想要对 Netty 掌握的更深的话,推荐你看一下这本书。
《Netty 入门与实战:仿写微信 IM 即时通讯系统》
通过一个基于 Netty 框架实现 IM 核心系统为引子,带你学习 Netty。整个小册的质量还是很高的,即使你没有 Netty 使用经验也能看懂。
搜索引擎
搜索引擎用于提高搜索效率,功能和浏览器搜索引擎类似。比较常见的搜索引擎是 Elasticsearch(推荐) 和 Solr。
如果你要学习 Elasticsearch 的话,Elastic 中文社区 以及 Elastic 官方博客 都是非常不错的资源,上面会分享很多具体的实践案例。
除此之外,极客时间的《Elasticsearch 核心技术与实战》这门课程非常赞!这门课基于 Elasticsearch 7.1 版本讲解,比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!


如果你想看书的话,可以考虑一下 《Elasticsearch 实战》 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。


如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的《Elasticsearch 源码解析与优化实战》这本书。这是市面上唯一一本写 Elasticsearch 源码的书。


分布式
下面我们开始学习分布式以及高并发、高可用了。
这块内容的话,对于每一个知识点没有特定的书籍。我就推荐 2 本我觉得还不错的书籍吧!这两把书籍基本把下面涉及到的知识点给涵盖了。
第一本是李运华老师的**《从零开始学架构》** 。


这本书对应的有一个极客时间的专栏—《从零开始学架构》,里面的很多内容都是这个专栏里面的,两者买其一就可以了。
第二本是余老师的 《软件架构设计:大型网站技术架构与业务架构融合之道》 。


事务与锁、分布式(CAP、分布式事务……)、高并发、高可用这本书都有介绍到。值得推荐!良心好书!
理论
CAP 理论
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
关于 CAP 的详细解读请看:《CAP 理论解读》。
BASE 理论
BASE 是 Basically Available(基本可用) 、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
关于 CAP 的详细解读请看:《BASE 理论解读》。
Paxos 算法和 Raft 算法
Paxos 算法诞生于 1990 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了 2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—Raft 算法。
RPC
RPC 让调用远程服务调用像调用本地方法那样简单。
Dubbo 是一款国产的 RPC 框架,由阿里开源。相关阅读:
服务注册与发现
Eureka、Zookeeper、Consul、Nacos 都可以提供服务注册与发现的功能。
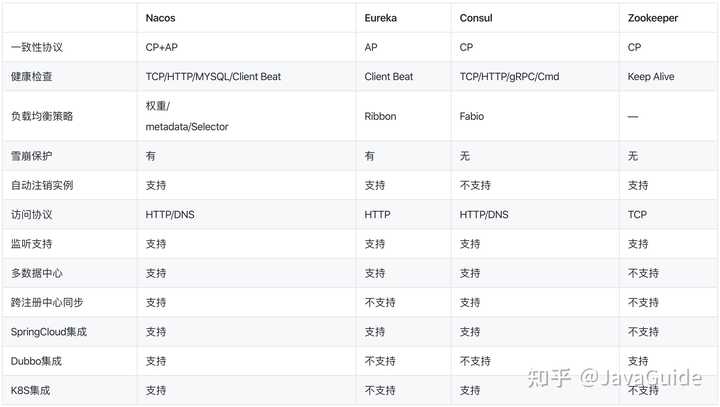
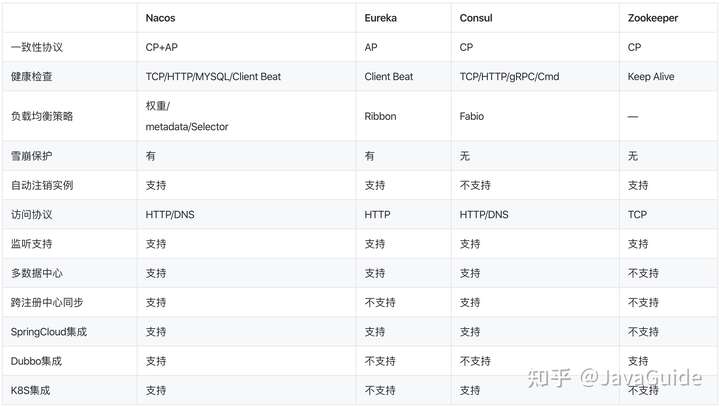
API 网关
网关主要用于请求转发、安全认证、协议转换、容灾。
SpringCloud Gateway 是 Spring Cloud 的一个全新项目,为了取代 Netflix Zuul。
配置中心
微服务下,业务的发展一般会导致服务数量的增加,进而导致程序配置(服务地址、数据库参数等等)增多。
传统的配置文件的方式已经无法满足当前需求,主要有两点原因:一是安全性得不到保障(配置放在代码库中容易泄露);二是时效性不行 (修改配置需要重启服务才能生效)。
Spring Cloud Config、Nacos 、Apollo、K8s ConfigMap 都可以用来做配置中心。
Apollo 和 Nacos 我个人更喜欢。Nacos 使用起来更加顺手,Apollo 在配置管理方面做的更加全面。
分布式 id
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
简单来说,ID 就是数据的唯一标识。
分布式 ID 是分布式系统下的 ID。分布式 ID 不存在与现实生活中,属于计算机系统中的一个概念。
我简单举一个分库分表的例子。
我司的一个项目,使用的是单机 MySQL 。但是,没想到的是,项目上线一个月之后,随着使用人数越来越多,整个系统的数据量将越来越大。
单机 MySQL 已经没办法支撑了,需要进行分库分表(推荐 Sharding-JDBC)。
在分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?
这个时候就需要生成分布式 ID了。
分布式 ID 的解决方案有很多比如 :
- 算法 :UUID、Snowflake
- 开源框架 : UidGenerator、Leaf 、Tinyid
分布式事务
微服务架构下,一个系统被拆分为多个小的微服务。
每个微服务都可能存在不同的机器上,并且每个微服务可能都有一个单独的数据库供自己使用。这种情况下,一组操作可能会涉及到多个微服务以及多个数据库。
举个例子:电商系统中,你创建一个订单往往会涉及到订单服务(订单数加一)、库存服务(库存减一)等等服务,这些服务会有供自己单独使用的数据库。
那么如何保证这一组操作要么都执行成功,要么都执行失败呢?
这个时候单单依靠数据库事务就不行了!我们就需要引入 分布式事务 这个概念了!
常用分布式事务解决方案有 Seata 和 Hmily。
分布式链路追踪
不同于单体架构,在分布式架构下,请求需要在多个服务之间调用,排查问题会非常麻烦。我们需要分布式链路追踪系统来解决这个痛点。
目前分布式链路追踪系统基本都是根据谷歌的《Dapper 大规模分布式系统的跟踪系统》这篇论文发展而来,主流的有 Pinpoint,Skywalking ,CAT(当然也有其他的例如 Zipkin,Jaeger 等产品,不过总体来说不如前面选取的 3 个完成度高)等。
Zipkin 是 Twitter 公司开源的一个分布式链路追踪工具,Spring Cloud Sleuth 实际是基于 Zipkin 的。
SkyWalking 是国人吴晟(华为)开源的一款分布式追踪,分析,告警的工具,现在是 Apache 旗下开源项目
微服务
微服务的很多东西实际在分布式这一节已经提到了。
我这里就再补充一些微服务架构中,经常使用到的一些组件。
- 声明式服务调用 : Feign
- 负载均衡 : Ribbon
- ……
高并发
消息队列
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读:消息队列常见问题总结。
常用的消息队列如下:
- RocketMQ :阿里巴巴开源的一款高性能、高吞吐量的分布式消息中间件。
- Kafaka: Kafka 是一种分布式的,基于发布 / 订阅的消息系统。关于它的入门可以查看:Kafka 入门看这一篇就够了
- RabbitMQ :由 erlang 开发的基于 AMQP(Advanced Message Queue 高级消息队列协议)协议实现的消息队列。
读写分离&分库分表
读写分离主要是为了将数据库的读和写操作分不到不同的数据库节点上。主服务器负责写,从服务器负责读。另外,一主一从或者一主多从都可以。
读写分离可以大幅提高读性能,小幅提高写的性能。因此,读写分离更适合单机并发读请求比较多的场景。
分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。
常见的分库分表工具有:sharding-jdbc(当当)、TSharding(蘑菇街)、MyCAT(基于 Cobar)、Cobar(阿里巴巴)…。 推荐使用 sharding-jdbc。 因为,sharding-jdbc 是一款轻量级 Java 框架,以 jar 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
相关阅读: 读写分离&分库分表常见问题总结
负载均衡
负载均衡系统通常用于将任务比如用户请求处理分配到多个服务器处理以提高网站、应用或者数据库的性能和可靠性。
常见的负载均衡系统包括 3 种:
- DNS 负载均衡 :一般用来实现地理级别的均衡。
- 硬件负载均衡 : 通过单独的硬件设备比如 F5 来实现负载均衡功能(硬件的价格一般很贵)。
- 软件负载均衡 :通过负载均衡软件比如 Nginx 来实现负载均衡功能。
高可用
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的 。
相关阅读: 《如何设计一个高可用系统?要考虑哪些地方?》 。
限流&降级&熔断
限流是从用户访问压力的角度来考虑如何应对系统故障。限流为了对服务端的接口接受请求的频率进行限制,防止服务挂掉。比如某一接口的请求限制为 100 个每秒, 对超过限制的请求放弃处理或者放到队列中等待处理。限流可以有效应对突发请求过多。相关阅读:限流算法有哪些?
降级是从系统功能优先级的角度考虑如何应对系统故障。服务降级指的是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
熔断和降级是两个比较容易混淆的概念,两者的含义并不相同。
降级的目的在于应对系统自身的故障,而熔断的目的在于应对当前系统依赖的外部系统或者第三方系统的故障。
Hystrix 和 Sentinel 都能实现限流、降级、熔断。
Hystrix 是 Netflix 开源的熔断降级组件,Sentinel 是阿里中间件团队开源的一款不光具有熔断降级功能,同时还支持系统负载保护的组件。
两者都是主要做熔断降级 ,那么两者到底有啥异同呢?该如何选择呢?
Sentinel 的 wiki 中已经详细描述了其与 Hystrix 的区别,你可以看看。
排队
另类的一种限流,类比于现实世界的排队。玩过英雄联盟的小伙伴应该有体会,每次一有活动,就要经历一波排队才能进入游戏。
集群
相同的服务部署多份,避免单点故障。
超时和重试机制
一旦用户的请求超过某个时间得不到响应就结束此次请求并抛出异常。 如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法在处理请求。