1、【对线面试官】今天来聊聊Java注解
什么是注解?
- 注解在我的理解下,就是代码中的特殊标记,这些标记可以在编译、类加载、运行时被读取,并执行相对应的处理。
开发中用到的注
- 注解其实在开发中是非常常见的,比如我们在使用各种框架时(像我们Java程序员接触最多的还是Spring框架一套) ,就会用到非常多的注解,@Controller I@Param / @Select等等
- 一些项目也用到lombok的注解,@SIf4j/@Data等等
- 除了框架实现的注解,Java原生也有@ Overried、 @Deprecated、 @Functional Interface等基本注解
- 不过Java原生的基本注解大多数用于「标记」和「检查」
- 原生Java除了这些提供基本注解之外,还有一种叫做元Annotation(元注解),所谓的元Annotation就是用来修饰注解的
- 常用的元Annotation有@Retention和@Target
- @Retention注解可以简单理解为设置注解的生命周期,而@Target表示这个注解可以修饰哪些地方(比如方法、还是成员变量、还是包等等)
自己定义过的注解,在项目里边用的
- 嗯,写过的。背景是这样的:我司有个监控告警系统,对外提供了客户端供我们自己使用。监控一般的指标就是QPS、RT和错误嘛。
- 原生的客户端需要在代码里指定上报这会导致这种监控的代码会跟业务代码混合,比较恶心。
public void send(String userName) {
try {
// qps 上报
qps(params);
long startTime = System.currentTimeMillis();
// 构建上下文(模拟业务代码)
ProcessContext processContext = new ProcessContext();
UserModel userModel = new UserModel();
userModel.setAge("22");
userModel.setName(userName);
//...
// rt 上报
long endTime = System.currentTimeMillis();
rt(endTime - startTime);
} catch (Exception e) {
// 出错上报
error(params);
}
}
其实这种基础的监控信息,显然都可以通过AOP切面的方式去处理掉(可以看到都是方法级的)。而再用注解这个载体配置相关的信息,配合AOP解析就会比较优雅
要写自定义的注解,首先考虑我们是在什么时候解析这个注解。这就需要用到前面所说的@Retention注解,这个注解会修饰我们自定义注解生命周期。
@Retention注解传入的是RetentionPolic y枚举,该枚举有三个常量,分别是SOU RCE、 CLASS和RUNTIME
理解这块就得了解从.java文件到class文件再到class被jvm加载的过程了。下面的图描述着从.java文件到编译为class文件的过程
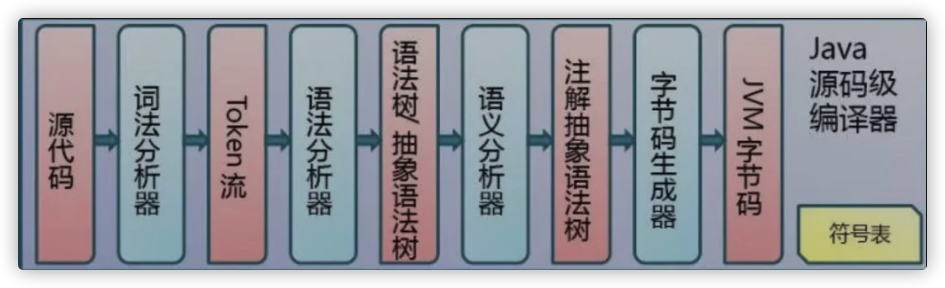
从上面的图可以发现有个「注解抽象语法树」,这里其实就会去解析注解,然后做处理的逻辑。
所以重点来了,如果你想要在编译期间处理注解相关的逻辑,你需要继承AbstractProcessor并实现process方法。比如可以看到lombok就用AnnotationProcessor继承了AbstractProcessor。
一般来说,只要自定义的注解中@Retention注解设置为SOURCE和CLASS这俩个级别,那么就需要继承并实现
因为SOURCE和CLASS这俩个级别等加载到jvm的时候,注解就被抹除了
从这里又引申出:lombok的实现原理就是在这(为什么使用了个@Data这样的注解就能有set/get等方法了,就是在这里加上去的)
自定义注解的级别
- 一般来说,我们自己定义的注解都是RUNTIME级别的,因为大多数情况我们是根据运行时环境去做一些处理。
- 我们现实在开发的过程中写自定义注解需要配合反射来使用
- 因为反射是Java获取运行时的信息的重要手段
- 所以,我当时就用了自定义注解,在SpringAOP的逻辑处理中,判断是否带有自定义注解,如果有则将监控的逻辑写在方法的前后
- 这样,只要在方法上加上我的注解,那就可以有对方法监控的效果(RT、QPS、ERROR)
@Around("@annotation(com.sanwai.service.openapi.monitor.Monitor)")
public Object antispan(ProceedingJoinPoint pjp) throws Throwable {
String functionName = pjp.getSignature().getName();
Map<String, String> tags = new HashMap<>();
logger.info(functionName);
tags.put("functionName", functionName);
tags.put("flag", "done");
monitor.sum(functionName, "start", 1);
//方法执行开始时间
long startTime = System.currentTimeMillis();
Object o = null;
try {
o = pjp.proceed();
} catch (Exception e) {
//方法执行结束时间
long endTime = System.currentTimeMillis();
tags.put("flag", "fail");
monitor.avg("rt", tags, endTime - startTime);
monitor.sum(functionName, "fail", 1);
throw e;
}
//方法执行结束时间
long endTime = System.currentTimeMillis();
monitor.avg("rt", tags, endTime - startTime);
if (null != o) {
monitor.sum(functionName, "done", 1);
}
return o;
}
总结
- 注解是代码的特殊标记,可以在编译、类加载、运行时被读取
- 其实对应的就是RetentionPolicy枚举三种级别
- SOURCE和CLASS级别需要继承AbstractProcessor,实现process方法去处理我们自定义的注解
- 而RUNTIME级别是我们日常开发用得最多了,配合Java反射机制可以在很多场景优化我们的代码
展示态度(嗯,总体来看,你对注解这块基础还是扎实的。)
- 主要是在工作中遇到注解的时候就多看看原理是怎么实现的,然后遇到业务机会,还是会写写,优化优化下代码