33、【对线面试官】Redis主从架构
要不你来讲讲你公司的Redis是什么架构的咯?
- 我前公司的Redis架构是「分片集群」,使用的是「Proxy」层来对Key进行分流到不同的Redis服务器上
- 支持动态扩容、故障恢复等等…
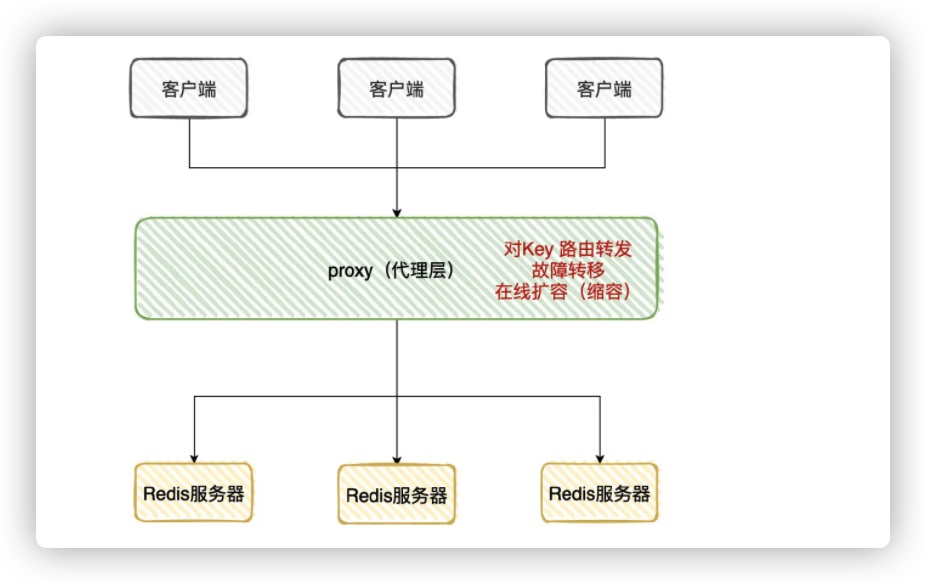
那你来聊下Proxy.层的架构和基本实现原理?
抱歉,这块由中间件团队负责,具体我也没仔细看过
不过,我可以给你讲讲现有常见开源的Redis架构
在之前提到了Redis有持久化机制,即便Redis重启了,可以依靠RDB或者AOF文件对数据进行重新加载
但在这时,只有一台Redis服务器存储着所有的数据,此时如果Redis服务器「暂时」没办法修复了,那依赖Redis的服务就没了
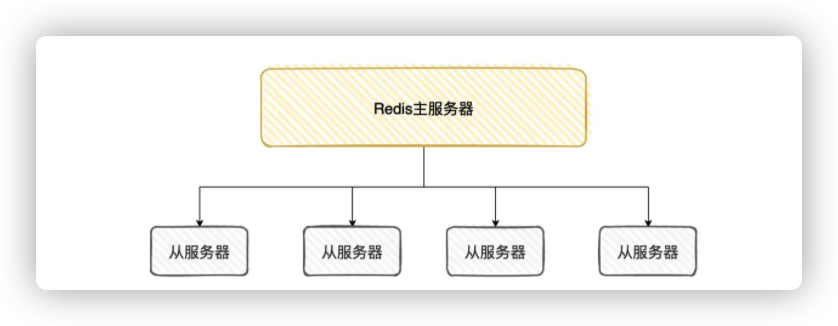
所以,为了Redis「高可用」,现在基本都会给Redis做「备份」:多启一台Redis服务器,形成「主从架构」
「从服务器」的数据由「主服务器」复制过去,主从服务器的数据是一致的
如果主服务器挂了,那可以「手动」把「从服务器」升级为「主服务器」,缩短不可用时间
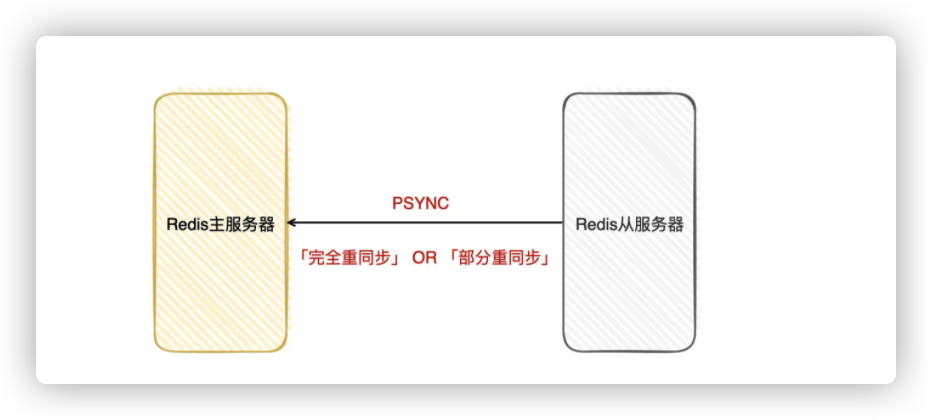
那「主服务器」是如何把自身的数据「复制」给「从服务器」的呢?
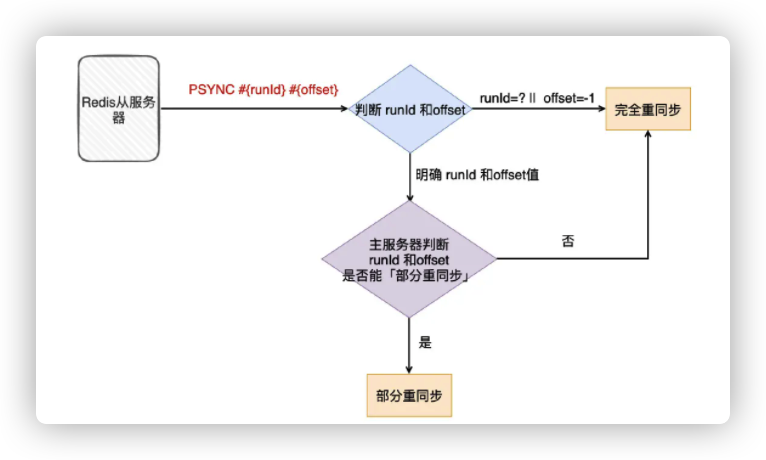
- 「复制」也叫「同步」,在Redis使用的是「PSYNC」命令进行同步,该命令有两种模型:完全重同步和部分重同步
- 可以简单理解为:如果是第一次「同步」,从服务器没有复制过任何的主服务器,或者从服务器要复制的主服务器跟上次复制的主服务器不一样,那就会采用「完全重同步」模式进行复制
- 如果只是由于网络中断,只是「短时间」断连,那就会采用「部分重同步」模式进行复制
- (假如主从服务器的数据差距实在是过大了,还是会采用「完全重同步」模式进行复制)
同步原理
主服务器要复制数据到从服务器,首先是建立Socket「连接」,这个过程会干一些信息校验啊、身份校验啊等事情
然后从服务器就会发「PSYNC」命令给主服务器,要求同步(这时会带「服务器ID」RUNID和「复制进度」offset参数。如果从服务器是新的,那就没有)
主服务器发现这是一个新的从服务器(因为参数没带上来),就会采用「完全重同步」模式,并把「服务器ID」(runld)和「复制进度」(offset)发给从服务器,从服务器就会记下这些信息。
随后,主服务器会在后台生成RDB文件,通过前面建立好的连接发给从服务器从服务器收到RDB文件后,首先把自己的数据清空,然后对RDB文件进行加载恢复
这个过程中,主服务器也没闲着(继续接收着客户端的请求)
主服务器把生成RDB文件「之后修改的命令」会用「ouffer.」记录下来,等到从服务器加载完RDB之后,主服务器会把「buffer.」记录下的命令都发给从服务器
这样一来,主从服务器就达到了数据一致性了(复制过程是异步的,所以数据是『最终一致性』)
那「部分重同步」的过程呢?
嗯,其实就是靠「offset」来进行部分重同步。每次主服务器传播命令的时候,都会把「offset」给到从服务器
主服务器和从服务器都会将「offset」保存起来(如果两边的offset存在差异,那么说明主从服务器数据未完全同步)
从服务器断连之后进行重连,就会发「PSYNC」命令给主服务器,同样也会带着RUNID和offset(重连之后,这些信息还是存在的)
主服务器收到命令之后,看RUNID是否能对得上,对得上,说明这可能以前就同步过一部分了
接着检查该「offset在主服务器里还是否存在(主服务器记录主从服务器offset的信息用的是环形buffer,如果该ouffer)满了,会覆盖以前的记录。而记录客户端的修改命令用的是另一个buffer)
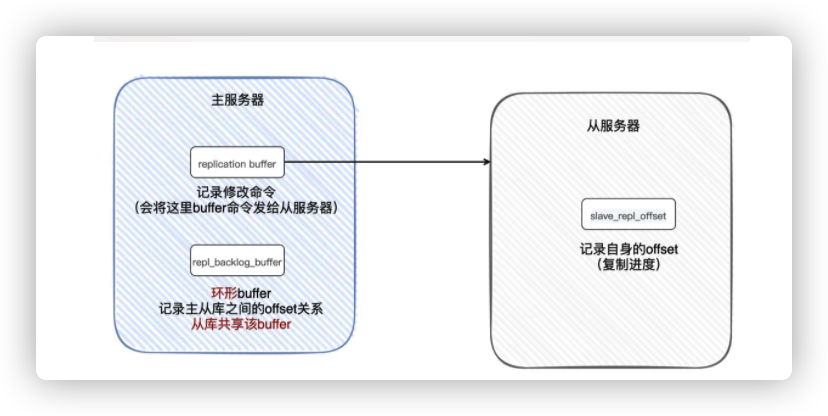
如果从backlog_buffer找到了,那就把从缺失的一部分offer开始,把对应的修改命令发给从服务器
如果从环形ouffer(backlog._buffer)没找到,那只能使用「完全重同步」模式再次进行主从复制了
懂了,无非就是有个关联关系记录下来,只不过存储是环形(可能会造成覆盖)
Redis主库如果挂了,你还是得「手动」将从库升级为主库啊?你知道有什么办法能做到「自动」进行故障恢复吗?
哨兵
「哨兵」干的事情主要就是:监控(监控主服务器的状态)、选主(主服务器挂了,在从服务器选出一个作为主服务器)、通知(故障发送消息给管理员)和配置(作为配置中心,提供当前主服务器的信息)
可以把「哨兵」当做是运行在「特殊」模式下的Redis服务器,为了「高可用」,哨兵也是集群架构的。
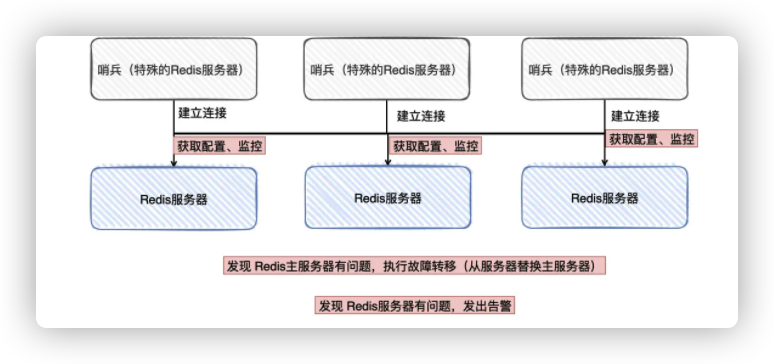
首先它需要跟Redis主从服务器创建对应的连接(获取它们的信息)
每个哨兵不断地用ping命令看主服务器有没有下线,如果主服务器在「配置时间」内没有正常响应,那当前哨兵就「主观」认为该主服务器下线了
其他「哨兵」同样也会ping该主服务器,如果「足够多」(还是看配置)的哨兵认为该主服务器已经下线,那就认为「客观下线」,这时就要对主服务器执行故障转移操作。
「哨兵」之间会选出一个「领头」,选出领头的规则也比较多,总的来说就是先到先得(哪个快,就选哪个)
由「领头哨兵」对已下线的主服务器进行故障转移
- 过程
- 首先要在「从服务器」上挑选出一个,来作为主服务器
- (这里也挑选讲究,比如:从库的配置优先级、要判断哪个从服务器的复制offset最大、RunID大小、跟master断开连接的时长…)
- 然后,以前的从服务器都需要跟新的主服务器进行「主从复制」
- 已经下线的主服务器,再次重连的时候,需要让他成为新的主服务器的从服务器
- 过程
了解,我想问问,Redis在主从复制和故障转移的过程中会导致数据丢失吗
会的
1)从上面的「主从复制」流程来看,这个过程是异步的(在复制的过程中:主服务器会一直接收请求,然后把修改命令发给从服务器)
假如主服务器的命令还没发完给从服务器,自己就挂掉了。这时候想要让从服务器顶上主服务器,但从服务器的数据是不全的
2)还有另一种情况就是:有可能哨兵认为主服务器挂了,但真实是主服务器并没有挂(网络抖动),而哨兵已经选举了一台从服务器当做是主服务器了,此时「客户端」还没反应过来,还继续写向旧主服务器写数据
等到旧主服务器重连的时候,已经被纳入到新主服务器的从服务器了…所以,那段时间里,客户端写进旧主服务器的数据就丢了
上面这两种情况(主从复制延迟&&脑裂),都可以通过配置来「尽可能」避免数据的丢失
(达到一定的阈值,直接禁止主服务器接收写请求,企图减少数据丢失的风险)
要不再来聊聊Redis分片集群?
- 分片集群就是往每个Redis服务器存储一部分数据,所有的Redis服务器数据加起来,才组成完整的数据(分布式)
- 要想组成分片集群,那就需要对key进行「路由」(分片)
- 现在一般的路由方案有两种:「客户端路由」(SDK)和「服务端路由」(Proxy)
- 客户端路由的代表(Redis Cluster),服务端路由的代表(Codis)
- 区别?
总结
Redis实现高可用:
- AOF/RDB持久化机制
- 主从架构(主服务器挂了,手动由从服务器顶上)
- 引入哨兵机制自动故障转义
主从复制原理:
- PSYNC命令两种模式:完全重同步、部分重同步
- 完全重同步:主从服务器建立连接、主服务器生成RDB文件发给从服务器、主服务器不阻塞(相关修改命令记录至buffer)、将修改命令发给从服务器
- 部分重同步:从服务器断线重连,发送RunId和offset给主服务器,主服务器判断offset和runId,将还未同步给从服务器的offset相关指令进行发送
哨兵机制:
- 哨兵可以理解为特殊的Redis服务器,一般会组成哨兵集群
- 哨兵主要工作是监控、告警、配置以及选主
- 当主服务器发生故障时,会「选出」一台从服务器来顶上「客观下线」的服务器,由「领头哨兵」进行切换
数据丢失:
- Redis的主从复制和故障转移阶段都有可能发生数据丢失问题(通过配置尽可能避免)